MLPerf Inference v5.0: New Workloads & New Hardware
-
 Russ Fellows
Russ Fellows
The MLCommons consortium has just released the results of its MLPerf Inference v5.0 benchmarks, providing new data for IT consumers looking to deploy AI workloads either on premise or in the cloud. This latest round showcases progress in AI inference capabilities, with particular emphasis on large language models (LLMs) and specialized applications.
MLPerf v5.0 had 23 organizations submitting a significant volume of performance results across datacenter and edge categories. Notably, one organization submitted over 5,000 results for edge inferencing across diverse hardware, including Arm, AMD, Intel, and specialized consumer systems.
A clear shift is evident in benchmark focus from traditional computer vision tasks to large language models. While ResNet50 image recognition previously dominated submissions, Llama-2-70B has now become the most common benchmark, with submissions increasing 2.5x year-over-year.
Performance Improvements
Comparing MLPerf Inference v4.0 to v5.0 reveals substantial progress. These gains are attributed to advances in quantization techniques, newer and faster hardware accelerators, and continued inferencing software optimization techniques. With a greater focus on inferencing, the increased research and focus are helping to drive innovations for inferencing software, including open and closed source inferencing stacks.
Measuring year over year changes from MLPerf Inference v4.0 to v5.0; the median Llama 2 70B score doubled, and the top-performing system achieved a 3.3x performance increase. These gains stem from a combination of factors including new quantization techniques, new hardware accelerators and continuing improvements and optimizations of software inferencing tools.
MLPerf Inference v5.0 introduced four new benchmarks to address the increasing importance of larger LLMs and expansive context windows. Larger models, such as Llama-3.1-405B, demonstrate improved performance across diverse accuracy and capability tests, making them comparable to leading subscription models such as ChatGPT, Claude and others.
| Benchmark | Top Perf Gain (YoY) | Key Optimization Techniques |
|---|---|---|
| Llama-2-70B | 3.3x | MXFP4 quantization, distributed inference |
| Mixtral 8x7B | 2.1x | Sparse MoE optimizations |
| ResNet50 | 1.4x | Mixed precision, batch optimization |
| SDXL 1.0 | 1.8x | Flash Attention, pipeline parallelism |
Table 1: Key Changes and Performance Gains (Source: Signal65 using MLPerf data)
Based on Signal65’s experience, we have found that testing LLMs has rapidly evolved to accommodate larger context windows, often exceeding 20,000 tokens. This shift aligns with real-world use cases that involve deeper reasoning and complex interactions. While previous MLPerf tests were capped at 2,048 tokens, the new MLPerf benchmarks better reflect production scenarios involving extensive token processing.
In Figure 1, we show a comparison of the best results reported for each major hardware accelerator in the Datacenter Inferencing category. It is an interesting observation that AMD accelerators are showing near parity with NVIDIA H series GPUs. The AMD Mi300x delivers near NVIDIA’s H100 performance levels, while the Mi325x provides almost the same performance as NVIDIA’s H200 accelerator. Clearly, the upcoming NVDIA B200 provides significant processing performance gains compared to all existing accelerators as seen in the chart below.
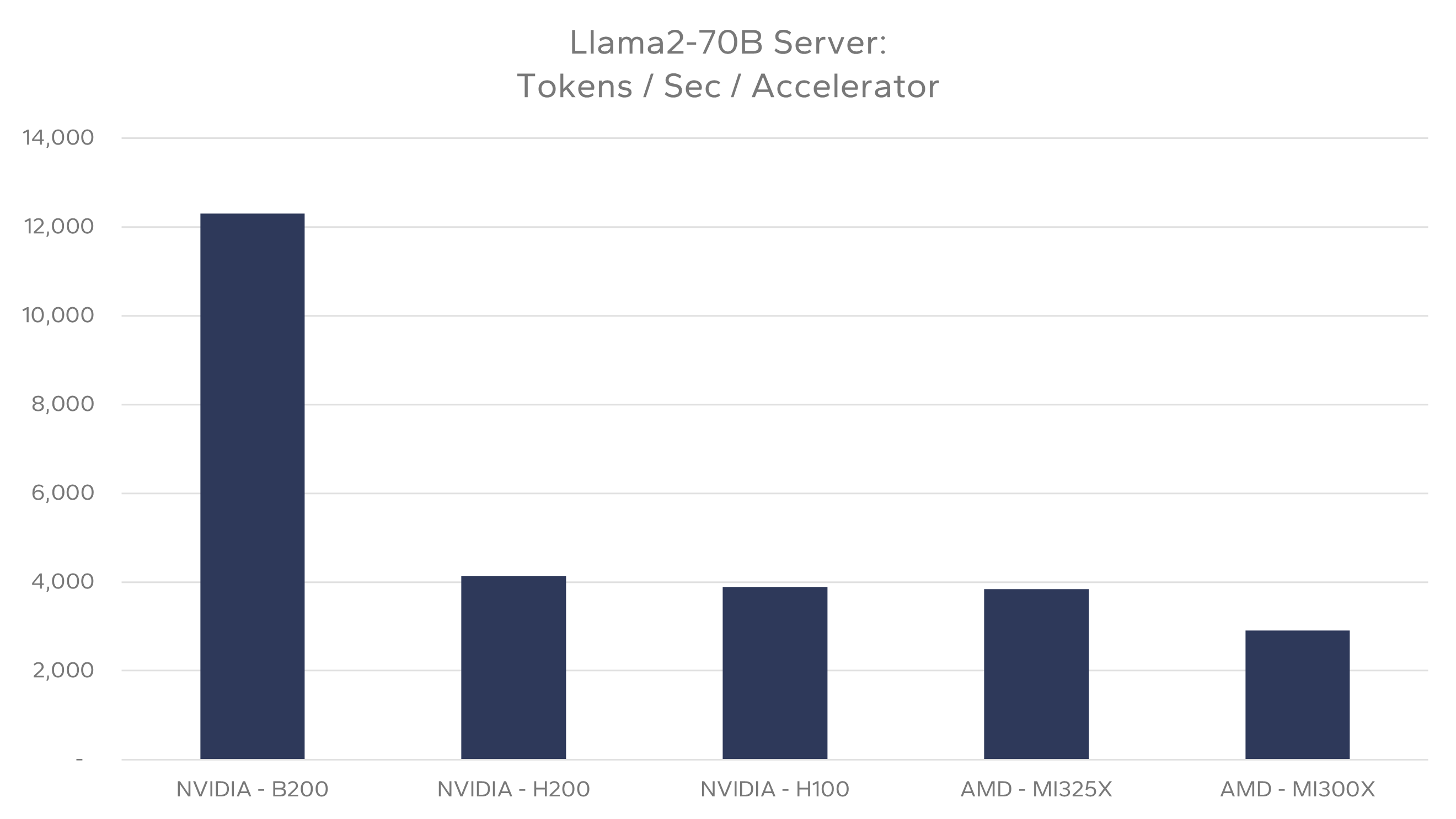
One additional note about these results is that the inferencing software stacks were different. Although the open source, vLLM supports NVIDIA, AMD and Intel Gaudi accelerators, the vLLM inferencing platform was primarily used by AMD when reporting their results. The vast majority of NVIDIA’s reported results utilized their proprietary TensorRT inferencing platform. Thus, it is difficult to directly compare the hardware accelerators performance directly, since there were both hardware and software stack differences between NVIDIA and AMD results.
New MLPerf Tests
Virtualized GPU Results
Broadcom released a set of results comparing the performance of a virtualized GPU to that of a GPU running on bare metal. The results, presented across several workloads, indicating that performance differences were less than 5% in every case, with some workloads showing only a 1% drop. This serves as significant proof of concept, demonstrating that utilizing virtual GPUs can provide performance comparable to bare metal, while also potentially increasing resource utilization rates. However, while the benchmark results show that running a single workload in a virtualized environment versus bare metal yields comparable performance, this does not necessarily reflect the performance of multiple AI workloads simultaneously sharing a virtualized GPU.
Llama-3.1-405B
As the largest LLM in the MLPerf suite, Llama-3.1-405B targets the demand for foundational models comparable to the leading subscription LLMs mentioned previously. Some of the key features of MLPerf’s testing for Llama-405B’s include:
- MLPerf expanded tokens, with new scenarios using a median input length of 9,500 tokens
- MLPerf imposed latency targets of 6 seconds for the first token and 175ms per output token (99th percentile) to help mimic real-time use case testing.
Llama-2-70B Interactive
Introduced in v4.0, the Llama-2-70B benchmark now includes an interactive variant aimed at real-time applications. Analysis of user data from platforms such as ChatGPT and Perplexity AI has driven aggressive latency targets:
- 450ms time-to-first-token (99th percentile).
- 40ms per output token (99th percentile), equivalent to 25 tokens per second per user.
The interactive benchmark emphasizes responsiveness, balancing user experience with system efficiency.
Relational Graph Attention Network (RGAT)
The RGAT benchmark acknowledges the growing importance of graph neural networks in fields like social networks and drug discovery. The benchmark is motivated by the increasing relevance of GNNs, especially in areas highlighted by computational chemistry research.
PointPainting for 3D Object Detection
This edge-focused benchmark targets autonomous vehicle use-cases, combining LiDAR and camera data for enhanced 3D object detection.
Hardware Innovations
New hardware accelerators, coupled with improved inferencing software demonstrated notable improvements in inference speed and efficiency. One notable hardware accelerator is NVIDIA’s B200 system, which showed approximately 3x higher performance on Llama-3.1-70B and Llama-3.1-405B compared to NVIDIA’s H200 systems, with only a 30% increase in power consumption. The AMD MI325X also achieved performance parity with NVIDIA’s H200 GPUs across various configurations and workloads.
New hardware entries in v5.0 include Google Trillium v6e TPU, NVIDIA B200 GPU, and Intel Xeon 6980P CPU, as well as the AMD Instinct MI325X, NVIDIA GB200, and NVIDIA Jetson AGX Thor.
Key Takeaways
The MLPerf Inference v5.0 results highlight several trends shaping AI Inferencing:
- Hardware Acceleration: Newer AI accelerators consistently outperform previous generations due to several factors including hardware and software improvements.
- Note: The gains from improved hardware vs. improved software are difficult to discern, due to how the data is presented.
- Software Optimization: Performance improvements rely heavily on integrating model architecture, quantization, and intelligently utilizing hardware resources
- User-Centric Metrics: The new interactive benchmarks prioritize responsiveness and efficiency.
- Model Diversity: Expanding benchmarks to cover graph neural networks and multi-modal systems reflects broader AI application use.
- Edge Computing: Increased submissions for edge devices indicate growing importance in AI deployment.
It is our belief that as AI models continue to expand and diversify, benchmarks will remain essential for evaluating hardware and software performance in real-world scenarios. MLPerf is providing important data points to help the market make better, and more informed decisions.



Tagged AI Workloads, MLPerf