From Dense to Mixture of Experts: The New Economics of AI Inference
-
 Ryan Shrout
Ryan Shrout
Executive Summary
The AI landscape is experiencing a shift from dense transformers to Mixture of Experts (MoE) models and reasoning-heavy workloads. A quick look at the Artificial Analysis leaderboard shows that the top 10 intelligent open-weight models are all MoE reasoning models. This shift is also actively reshaping inference economics and raising the stakes on inference platform choice and the viability of different AI services.
Inference economics are driven by how frontier models operate. To unlock higher intelligence, models generate massive volumes of “reasoning” tokens. For reasoning to be viable at scale, these tokens must be delivered at low per-token latency and cost. MoE architectures are designed to address this by activating only the relevant “experts” for each token and providing frontier-class intelligence without a proportional increase in compute cost.
What is the primary constraint of the MoE approach? A primary consideration is communication bottlenecks. With experts spread across GPUs, any delay in inter-GPU communication leaves GPUs idle, waiting for data. This idle time is wasted, inefficient compute that adds directly to the bottom line cost for service providers.
To understand the performance and economic impact of these shifts, we compared AI infrastructure options across different model architectures using publicly available benchmarks. Our findings show that NVIDIA B200 does outperform AMD MI355X configurations for dense architectures and smaller MoE models. But, when scaling to frontier-class models like DeepSeek-R1 beyond a single node, all 8-GPU systems (from both NVIDIA and AMD) hit a ‘scaling ceiling’ due to communication bottlenecks.
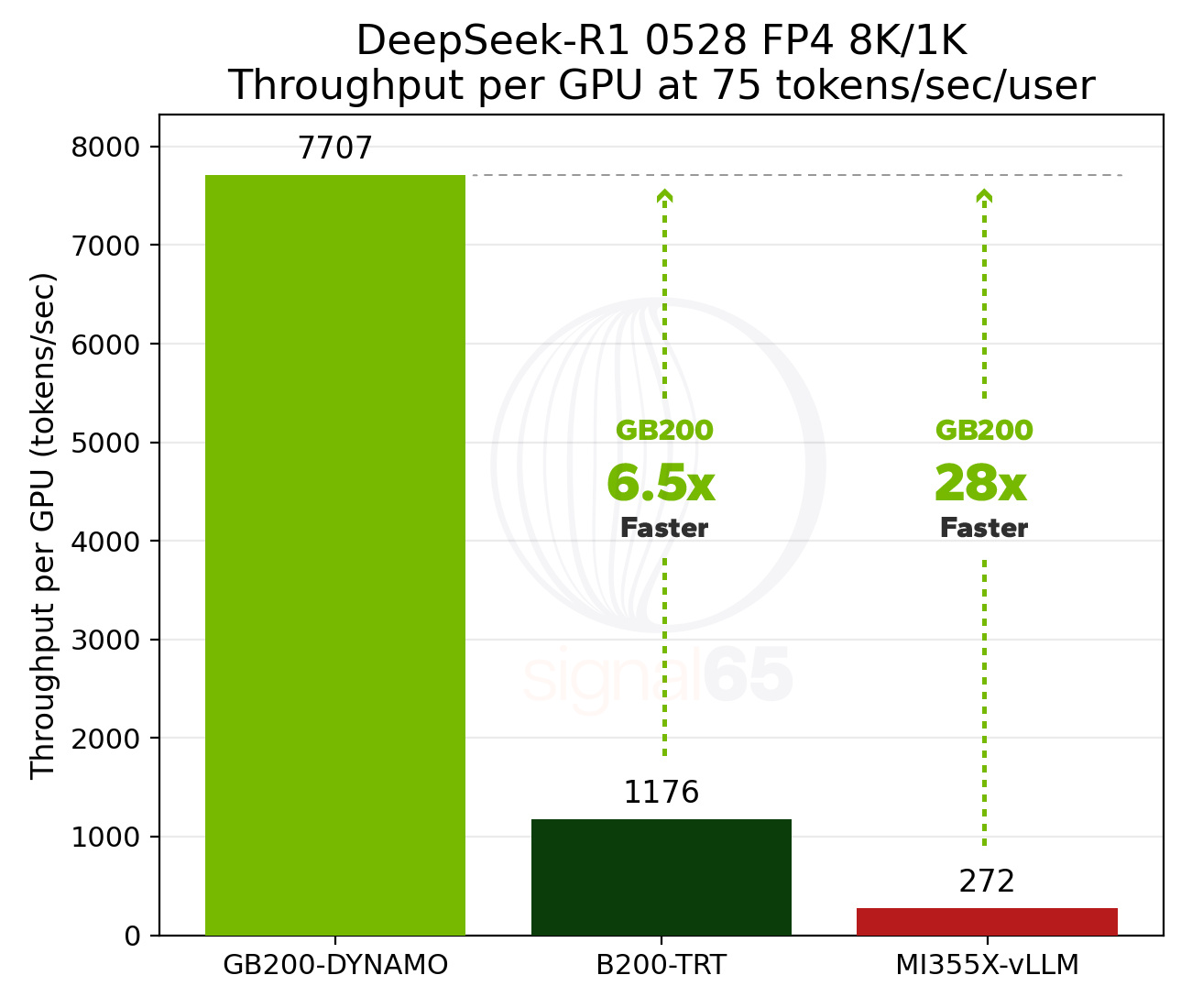
The NVIDIA GB200 NVL72 architecture appears to effectively address this scaling limitation. That same publicly available DeepSeek-R1 performance data shows that GB200 NVL72 delivers up to 28x the performance of the competing MI355X platform. How does this performance translate into cost-per-token? Our findings show that for high-interactivity reasoning workloads, the NVL72 delivers performance at as low as 1/15th the cost-per-token of other infrastructure options.
And though GB200 NVL72 carries a nearly 2x per-GPU hourly price compared to these competitive platforms, its rack-scale capabilities (from NVLink fabric to software orchestration across 72 GPUs) drive these superior unit economics. The value shifts from raw FLOPs to total intelligence per dollar.
The implication is direct: as complexity and scale rise with MoE models and reasoning, the industry can no longer rely on chip-level performance alone. End-to-end platform design that creates peak system-wide performance has become the primary lever for cost-effective, responsive AI.
Introduction
AI infrastructure technology evolves continuously as models, serving stacks, and user experience expectations change faster than traditional data center refresh cycles. This reality demands a new approach to infrastructure evaluation, one that emphasizes more frequent, comparable measurement over static assessments.
Total cost of ownership (TCO) and return on investment (ROI) arguments remain central to infrastructure decisions, but they only hold meaning when attached to measurable platform advantages under production workloads. Marketing claims and theoretical peak performance specifications tell an interesting but incomplete story; real-world inference serving under concurrency, with varied input/output patterns, reveals the performance reality of each platform.
When customers evaluate AI infrastructure economics, the conversation typically centers on three dimensions:
- Performance (throughput and interactivity)
- Energy efficiency (tokens generated per a given power budget)
- Total cost of ownership (cost to generate tokens, often expressed as cost per million tokens)
These three factors, along with either investment costs or monthly service costs, interlock to determine whether any AI service can be delivered profitably at scale.
In this analysis, we employ third-party benchmark-derived performance measurements to estimate relative token economics, rather than relying on vendor performance claims. We present a subset of results from the NVIDIA B200, NVIDIA GB200 NVL72, as well as the AMD MI355X, to see how they really compare in terms of performance across various models and resulting TCO estimates. Our approach follows a key simplifying principle: relative cost per token is driven by relative platform cost divided by relative token output at a given interactivity target. By keeping pricing assumptions transparent and separate from performance measurement, readers can adjust inputs based on their specific terms and deployment scenarios.
User Cost per M Tokens = User Cost GPU/hr / 3600 sec/hr / (TPS/GPU at an Interactivity) * 1,000,000
Data Analysis Process
This analysis uses publicly accessible benchmark data from the InferenceMAX platform, ensuring the conversation remains open and verifiable. From these data sweeps, we extract a set of observed results per platform, then focus on a subset of the most decision-relevant data points rather than presenting everything. We are looking at the best-case configurations and peak performance for each hardware platform: that means TensorRT-LLM for single node NVIDIA implementations and vLLM for AMD GPUs. For DeepSeek-R1 that shifts to Dynamo -TensorRT LLM results for NVIDIA and SGLang for AMD.
We will visualize results using pareto frontier analysis, which shows the best achievable tradeoffs between throughput per GPU and user interactivity for a given combination of variables. With these charts, as an AI infrastructure buyer, you can compare targeted token rates and see per-GPU performance levels to achieve it. As a consumer of AI, you care more about the x-axis, where the higher the interactivity translates into better user experiences.
But these full benchmark sweeps contain considerable complexity and can also be difficult to translate into actionable decisions. So, we are also presenting performance at key interactivity thresholds, what we call “bookends,” to anchor the analysis to scenarios that map directly to deployment decisions and quite frankly, make the data more consumable.
Throughout this paper, we use tokens per second per user as our practical proxy for responsiveness. This metric captures what matters most to end users: how quickly they receive generated content and the experience of engaging with a model or service. We establish interactivity thresholds as decision points rather than absolute truths, recognizing that different applications have different requirements for what constitutes an acceptable user experience. For each model analysis, we establish two bookends: one at the lower end of the interactivity spectrum and one at a higher point, unique to each model due to performance and data availability. For Llama 3.3 70B, for example, we chose 30 tokens/sec/user that represents a minimum for interactive usage, anchored to typical reading speed, while 110 tokens/sec/user represents near-peak interactivity where the experience feels fluid and responsive. GPT-OSS-120B has much higher bookends to account for its usage as a reasoning model. These are explained in each section below.
Establishing the Baseline: Dense Model Performance
Meta’s Llama 3.3 70B serves as our dense model reference point, a modern, high-capability large language model (LLM) widely relevant for both enterprise deployments and hosted inference services. We chose to use an 8K input / 1K output sequence length scenario, representing summarization-style workflows and light RAG patterns where service providers care about both concurrency economics and user experience quality. Comparing platforms using best-of software stacks per vendor (TensorRT-LLM for NVIDIA, vLLM for AMD), we isolate platform-level outcomes for real deployment decisions rather than conducting a framework comparison.
(Worth noting: when I was compiling this data for our analysis the latest run that included Llama 3.3 70B results was from late October 2025, so you’ll see that indicated with our charts below.)
NVIDIA B200 vs AMD MI355X
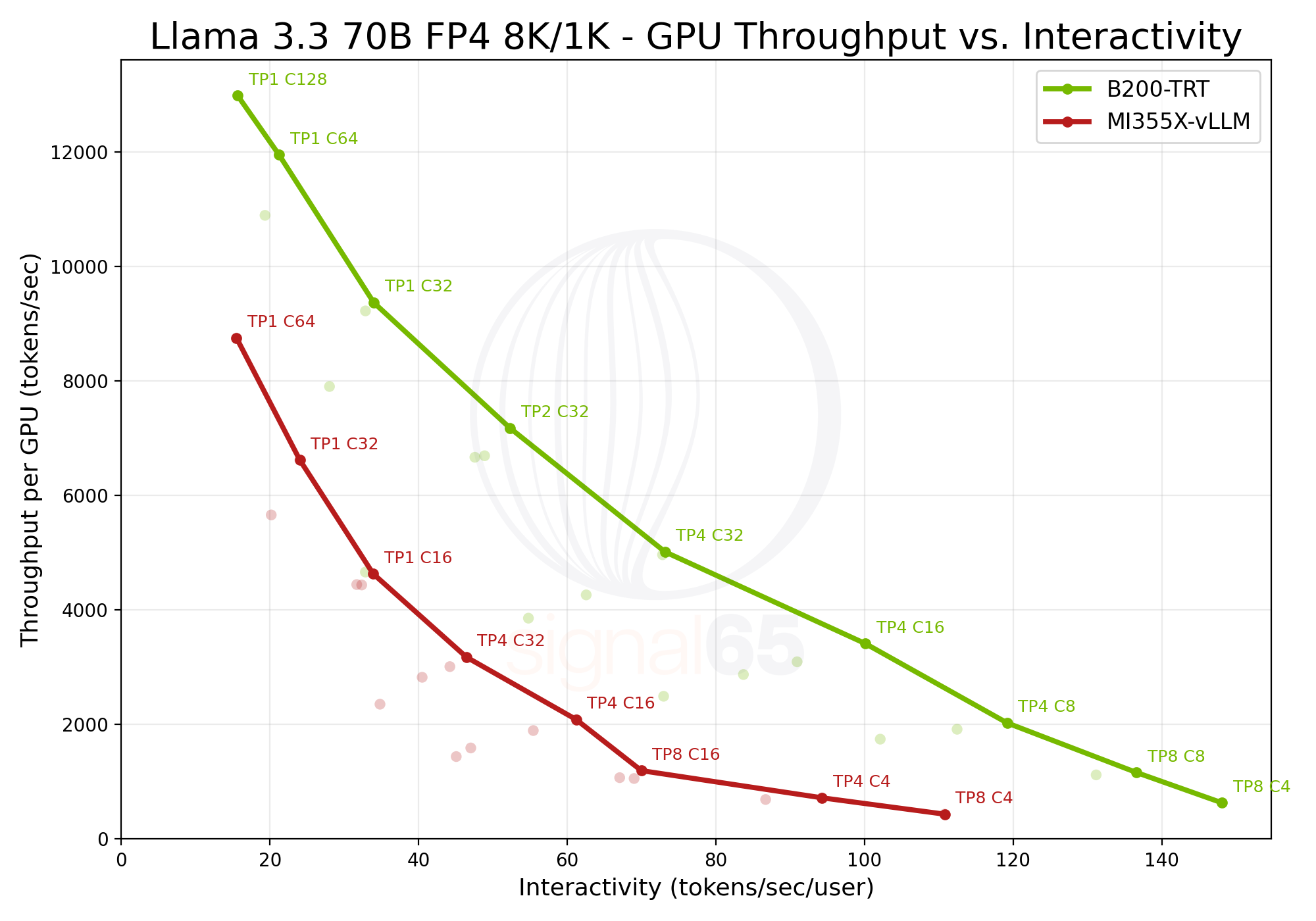
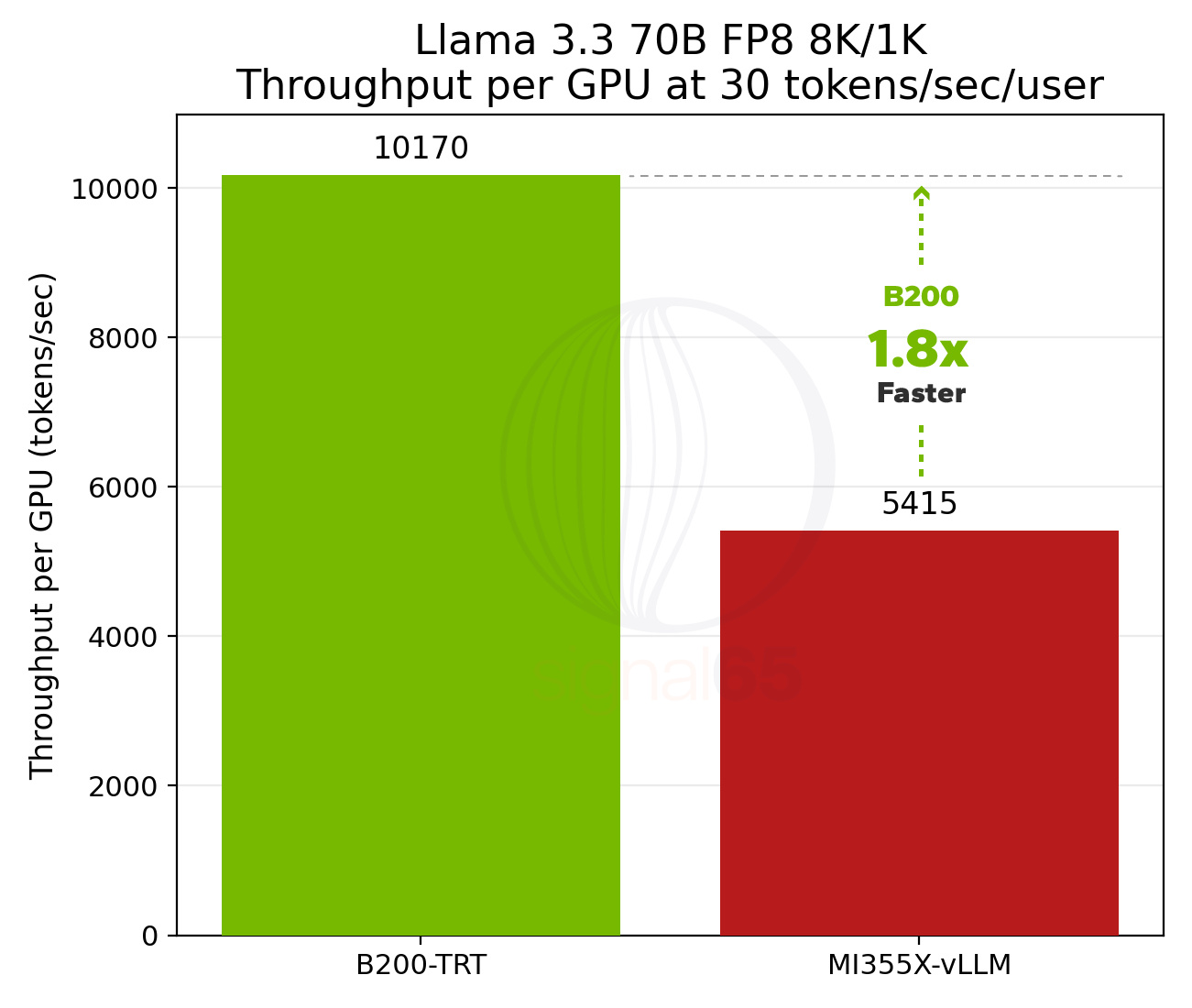
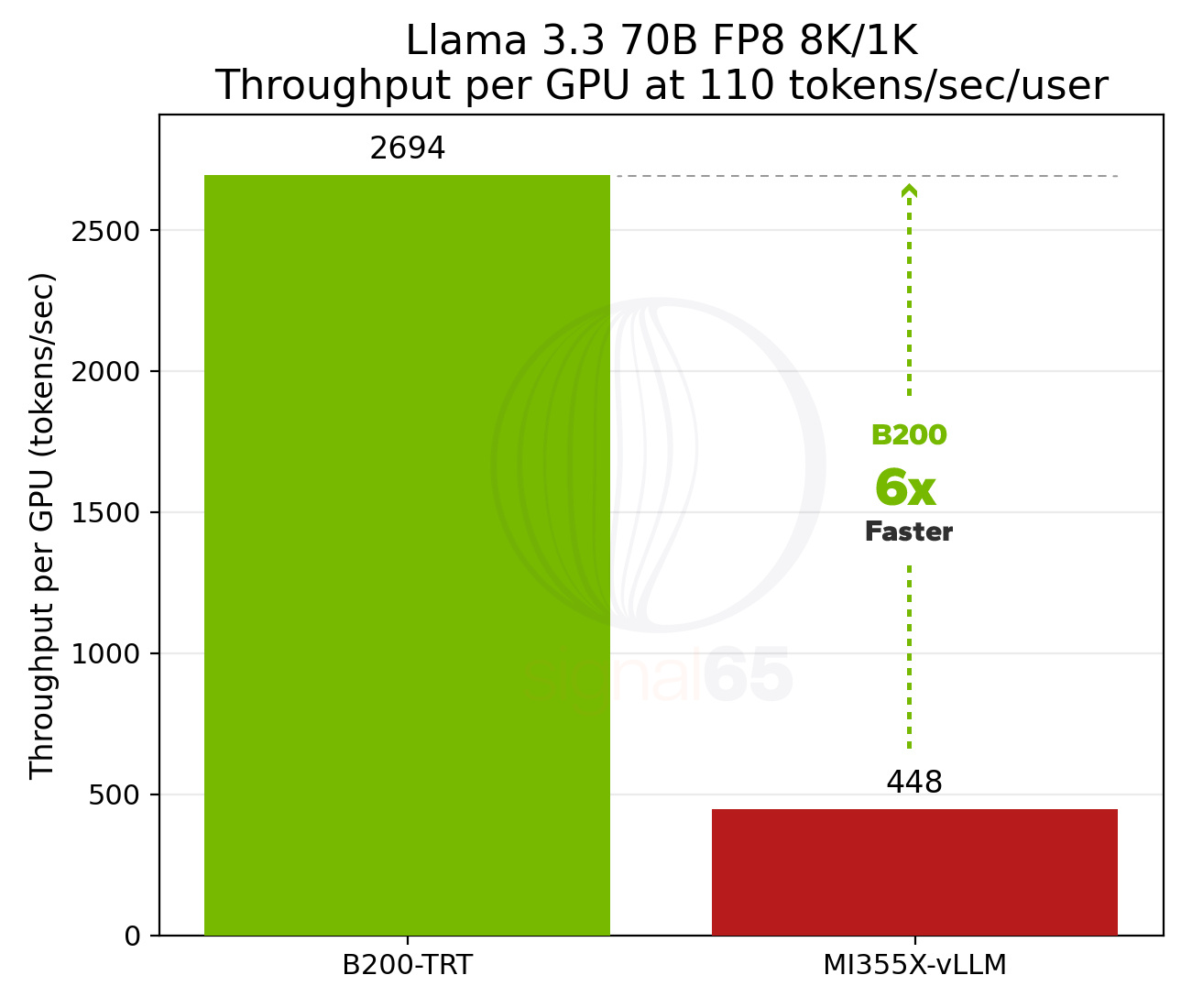
Looking at performance on these platforms, NVIDIA HGX B200 with TensorRT-LLM and AMD MI355X with vLLM, the pareto curve shows consistent performance advantages across the sweep of throughput per GPU and interactivity for the NVIDIA solution. Looking specifically at baseline interactivity, the B200 delivers approximately 1.8x higher performance than MI355X, providing significant headroom for interactive deployments and broader concurrency per GPU.
At 110 tokens/sec/user, the advantage becomes more pronounced: B200 delivers more than 6x the throughput of MI355X. This difference changes product design options entirely, enabling more responsive user experiences, faster agent loops, and higher premium tier density, capabilities that can directly impact service economics and competitive positioning.
In the Llama 3.3 70B dense model testing, we see that the AMD MI355X can offer competitive performance-per-dollar (based on pricing information we show at the end), but as you’ll see below that does not represent a test for more modern inference stacks, particularly those built around MoE architectures and reasoning-heavy workloads.
Understanding Mixture of Experts Architecture and Reasoning AI
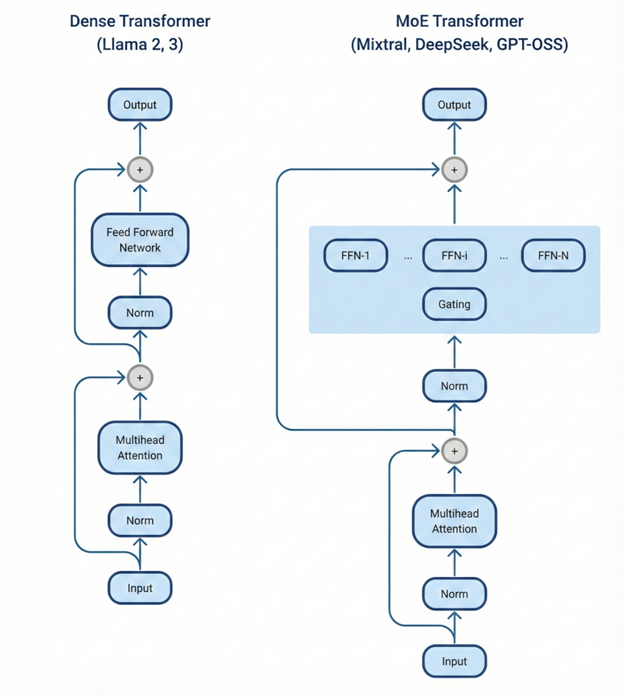
AI models have traditionally scaled intelligence by increasing the number of parameters in the model. Traditional dense model architectures required that every parameter in the model be activated for each token, meaning that as models continued to grow larger, they were slower and more costly to run with corresponding increases in required memory, etc.
Mixture-of-experts (MoE) model architectures differ from dense model architectures in that the model’s parameters are subdivided into many specialized subnetworks, referred to as “experts.” MoE models incorporate a lightweight router that determines which sets of experts to activate on a per-token basis, significantly reducing the computational cost per token for a given level of intelligence.
At the same time, many of the most prominent MoE models are also reasoning models, which apply additional compute during the inference process to increase accuracy. Instead of emitting an answer immediately, they generate intermediate reasoning tokens before producing user-visible output, effectively “thinking” through the request and solutions first. Those reasoning tokens often greatly outnumber the final response and may not be shown to the user at all. (Though they can offer interesting insight into how the model came to its conclusions and its actions.) As a result, total token generation per request rises, meaning that the ability to generate tokens both quickly and cost-effectively is critical for inference deployments.
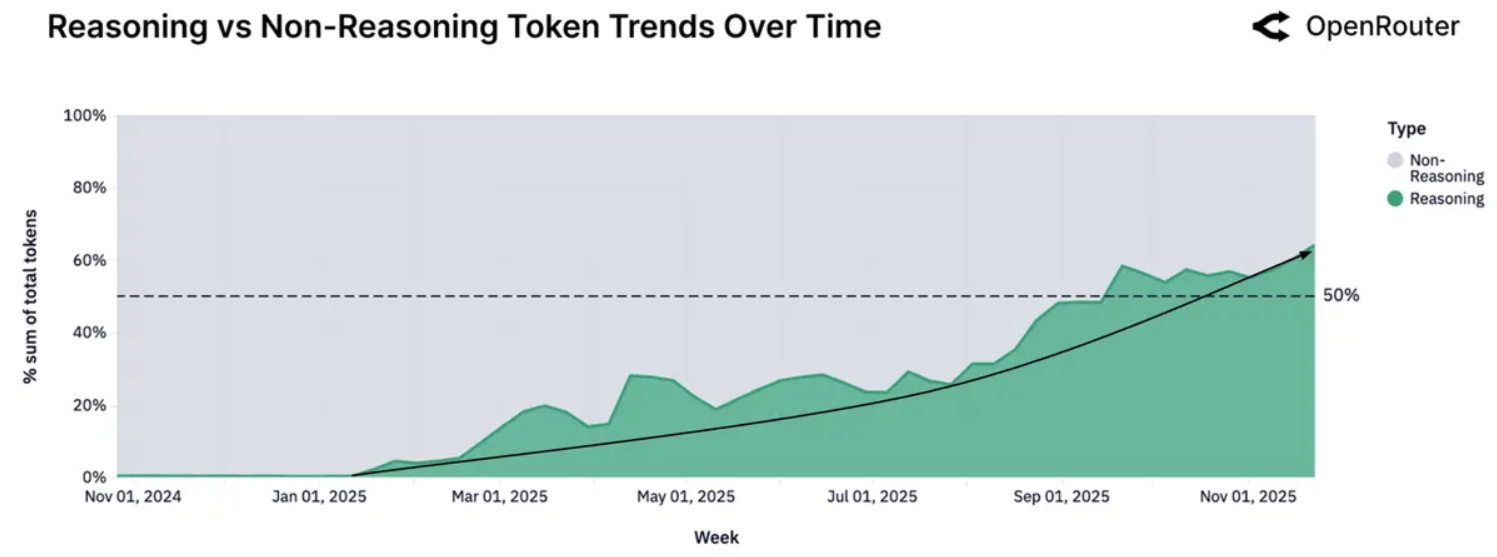
According to a recent report from OpenRouter, more than 50% of tokens are routed through reasoning models.
The massive adoption of MoE architecture and reasoning by frontier models is also evident in the Artificial Analysis leaderboard where the most intelligent open weights models, which include DeepSeek, Kimi K2 Thinking, and GPT-OSS-120B, are reasoning MoEs.

Serving MoE models introduces complexities that dense models do not. Performance becomes significantly more sensitive to routing efficiency, load balance across experts, and scheduling decisions, particularly under concurrent load. As reasoning has become common, performance depends increasingly on sustained interactivity at rack scale rather than peak single-node throughput.
MoE also makes the idea of “tokenomics” and TCO considerations more visible. Routing, scheduling, and communication overheads can substantially reduce real-world throughput under concurrency. The economic story remains focused on sustained tokens per second per GPU at defined user experience targets, but now how well performance scales beyond a single 8-GPU node is more critical.
Moderate Reasoning MoE Performance: gpt-oss-120B
OpenAI gpt-oss-120B, an open model from OpenAI, represents an ideal bridge example for understanding MoE serving characteristics. Large enough to surface MoE complexity, it remains something many teams can realistically deploy and tune. It occupies a useful midpoint between dense 70B class models and the newer frontier reasoning MoE architectures to which the market is rapidly moving.
The model architecture includes 36 layers with 117B total parameters, but only approximately 5.1B active parameters per token through its 128 total experts (4 active per token) design. It supports context lengths up to 128K tokens, making it useful for enterprise document processing and extended reasoning tasks.
With MoE models, especially when reasoning is involved, high perceived interactivity often requires a higher tokens/sec/user threshold than one-shot dense summarization prompts. For this analysis, we establish new bookends: 100 tokens/sec/user as practical usable reasoning interactivity, and 250 tokens/sec/user as a higher tier where the experience becomes meaningfully faster for reasoning loops and agent workflows. We analyze a 1K input / 8K output scenario, a reasoning-weighted pattern where long generation matters more than quick one-shot answers. These configurations tend to magnify differences in scheduling, memory, and end-to-end serving.

Our data includes both late October and early December measurements, and the conclusions shift as both NVIDIA and AMD software stacks improve. This illustrates an important dynamic: platform performance is not static, and software optimization can lift GPU performance. However, the relative gap can still change, especially at higher interactivity targets.
In late October measurements, at the 100 tokens/sec/user threshold, NVIDIA B200 was about 1.4x faster than MI355X, a meaningful but not dramatic advantage. At 250 tokens/sec/user, however, the gap grows substantially to approximately 3.5x, demonstrating how higher interactivity targets can amplify platform differences.
Early December data tells a different story. Both platforms improved significantly in absolute terms thanks to software optimizations, NVIDIA’s peak throughput per GPU jumped from approximately 7,000 tokens/sec to over 14,000, while AMD improved from around 6,000 to roughly 8,500 tokens/sec. That is good news for the industry as a whole.
Source: SemiAnalysis InferenceMAX GitHub, Date: Dec 4, 2025 (Note these bookends cover the Dec’25 data set only.)
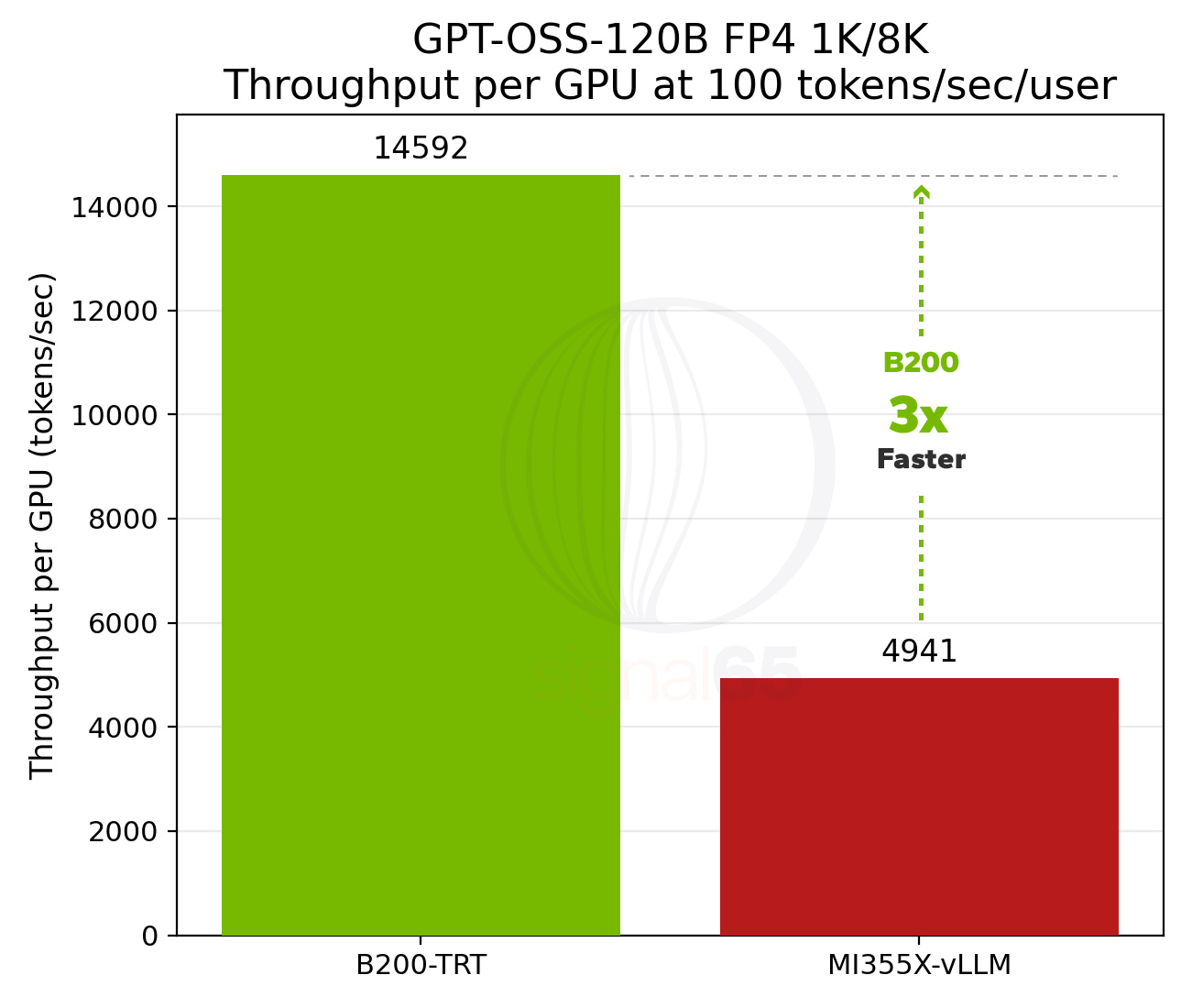
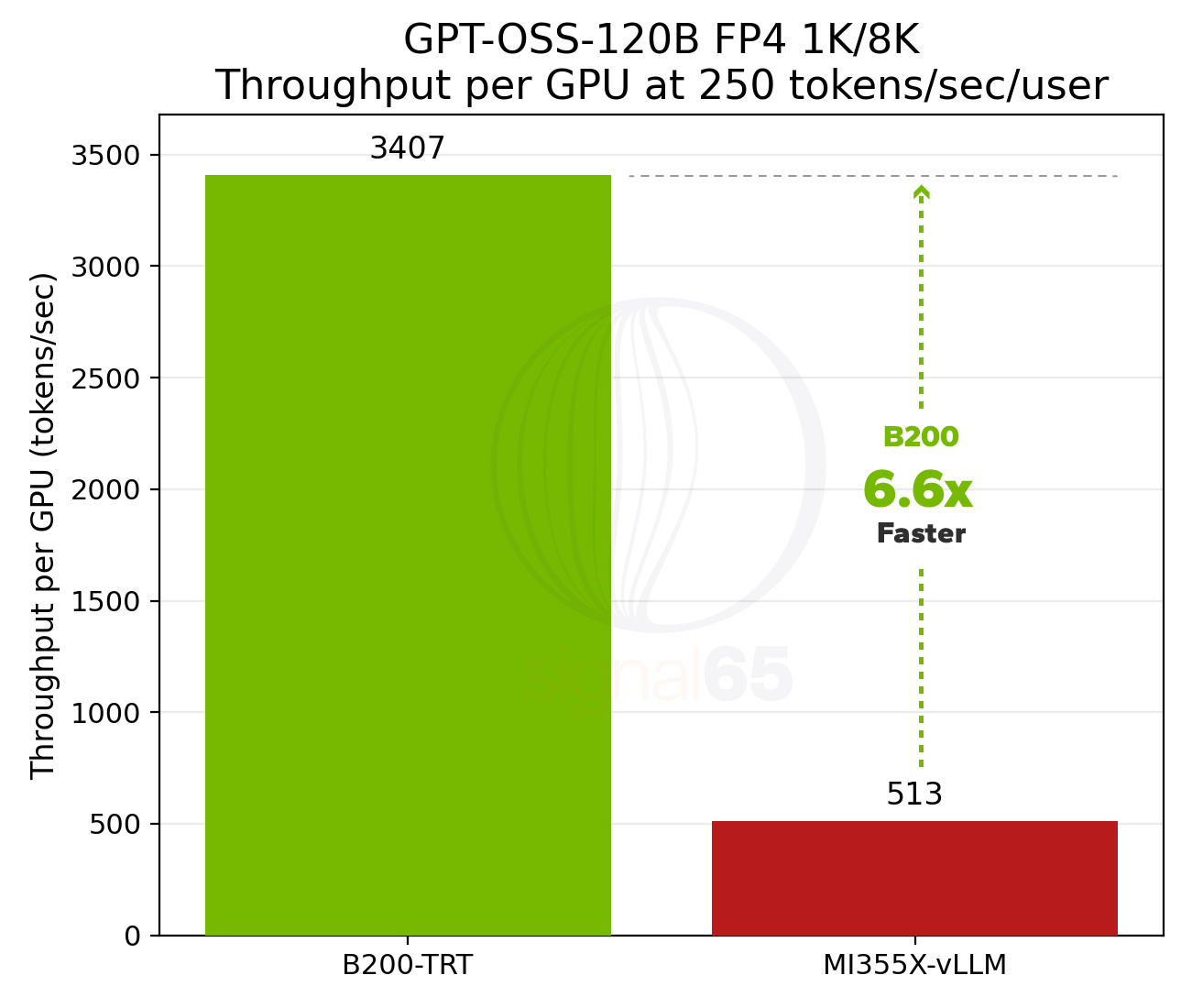
However, the relative gap also changed. At 100 tokens/sec/user interactivity, B200 now delivers nearly 3x the performance of MI355X, up from 1.4x in the October InferenceMAX data. At 250 tokens/sec/user, more representative of reasoning model requirements, the B200 advantage increases to 6.6x.
The takeaway is clear: dense model performance differentials are meaningful, but MoE differentials become larger as you push toward fast reasoning interactivity targets. This naturally raises the question: if these gaps emerge in a moderate MoE model, what happens with larger reasoning-focused MoE architectures like DeepSeek-R1?
Frontier Reasoning MoE Performance: DeepSeek-R1
DeepSeek-R1 is a reasoning-specialized model family built as a modern MoE, making it a good proxy for frontier inference direction. It represents the intersection of three trends that stress infrastructure: MoE routing, large parameter scale (671B total parameters, 37B activated), and demanding reasoning-style generation requirements.
Real-world serving challenges surface quickly with models of this class: higher concurrency targets, longer outputs, heavier key value (KV) cache pressure, and more sensitivity to scheduling and communication efficiency. Frontier model roadmaps increasingly prioritize reasoning, test-time compute, and sparse or modular architectures, all factors that amplify the need for platform-level scale and sophisticated serving software orchestration.
Very large reasoning MoE models push beyond what 8-GPU tensor parallel configurations can address effectively. At that point, expert parallelism and more recently wide expert parallelism become the necessary scaling mechanism, because experts and routing decisions must be distributed across many GPUs to sustain throughput and interactivity. Even when a single node performs well on dense or moderate MoE workloads, models like DeepSeek-R1 can use much more. Communication and orchestration become first-order performance constraints, and these models are less forgiving of suboptimal routing, KV cache handling, and GPU utilization gaps. The result is a widening separation between “good single-node performance” and “good multi-node scaled performance.” This is where rack-scale architecture stops being a nice-to-have and becomes a must-have.
NVIDIA GB200 NVL72: Rack-Scale Architecture Performance
NVIDIA GB200 NVL72 brought change to the scaling ceiling. By connecting 72 GPUs in a single NVLink domain, the system essentially functions at a software level as one massive GPU at rack scale. (As a side note, I admit that this felt purely like marketing language when I first heard it, but the data is proving it out.) This design enables tensor parallel scaling well beyond the 8-GPU ceiling of B200 and MI355X single-node systems, fundamentally increasing what performance is achievable.
The NVLink Switch fabric provides 130 TB/s of interconnect bandwidth, allowing every GPU to communicate with minimal latency. For MoE models, this means experts distributed across dozens of GPUs can execute in all-to-all communication patterns, precisely what these architectures require for efficient serving.
NVIDIA Dynamo, used in the NVL72 testing from InferenceMAX, exemplifies how serving software becomes integral to the platform story. Designed for multi-node inference with high throughput and low latency, Dynamo implements disaggregated prefill and decode phases, dynamic scheduling, and KV cache routing. This system-plus-software integration is what transforms raw GPU capability into scalable reasoning throughput.
Comparing current-generation platforms against prior-generation alternatives highlights platform ROI more clearly than a same-generation head-to-head analysis alone. It can show how much performance headroom a newer platform can unlock at identical interactivity targets, reinforcing that performance is not just about individual GPUs, but rather how architecture, system design, and software combine into a usable throughput per GPU capability.
Our comparison includes new, modern platforms (GB200, B200, MI355X) running FP4-quantized DeepSeek-R1 against prior-generation platforms (H200, MI325X) running FP8 versions. This reflects real-world deployment decisions: newer stacks typically adopt more aggressive quantization earlier to maximize throughput per dollar. The goal is not a perfect apples-to-apples comparison but rather understanding what level of usable interactivity each platform generation can deliver.
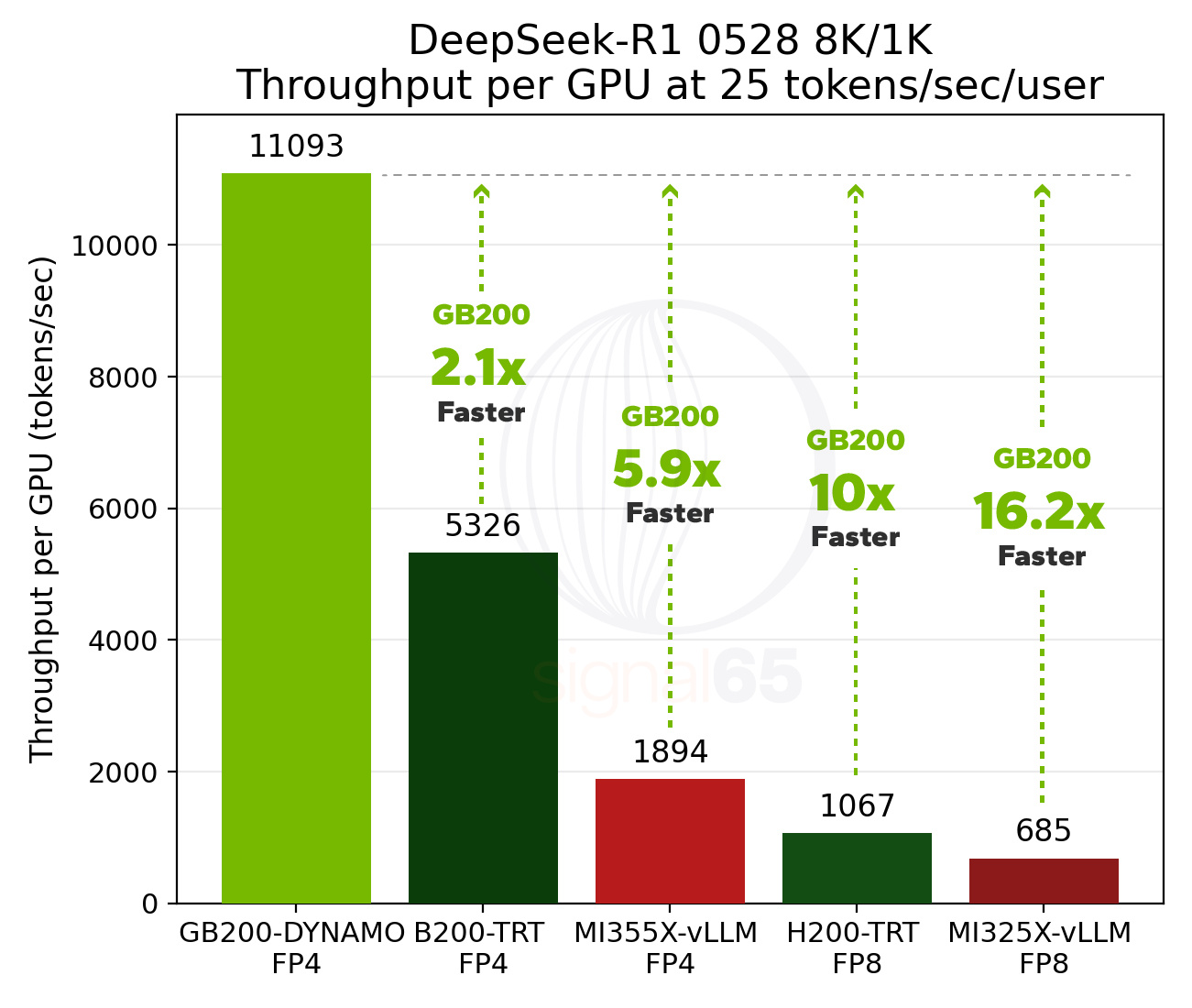
The benchmark data reveals a transformed landscape. GB200 NVL72 enables tensor parallelism configurations of more than eight GPUs to achieve Pareto frontier performance, achieving performance levels that single-node platforms simply cannot match. Our traditional bookend comparison methodology struggles here because B200 scales well beyond MI355X, and the Pareto curves increasingly diverge.
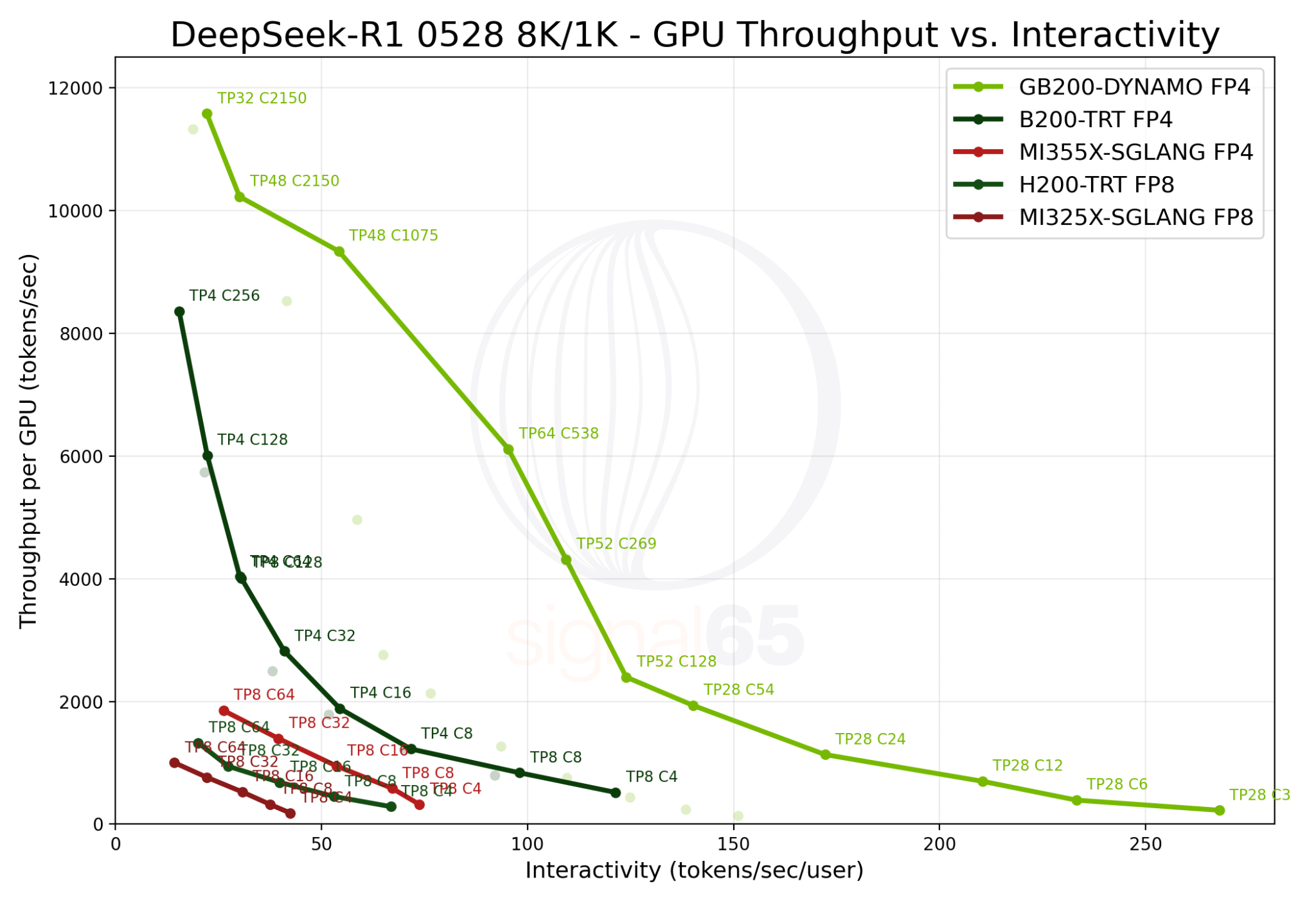
At 25 tokens/sec/user interactivity, GB200 NVL72 provides approximately 10x the performance per GPU of latest H200 results and more than 16x the performance per GPU of the MI325X platforms. These are the kinds of performance differences that create dramatic TCO improvements for AI service providers.
Source: SemiAnalysis InferenceMAX GitHub, Date: Dec 4, 2025
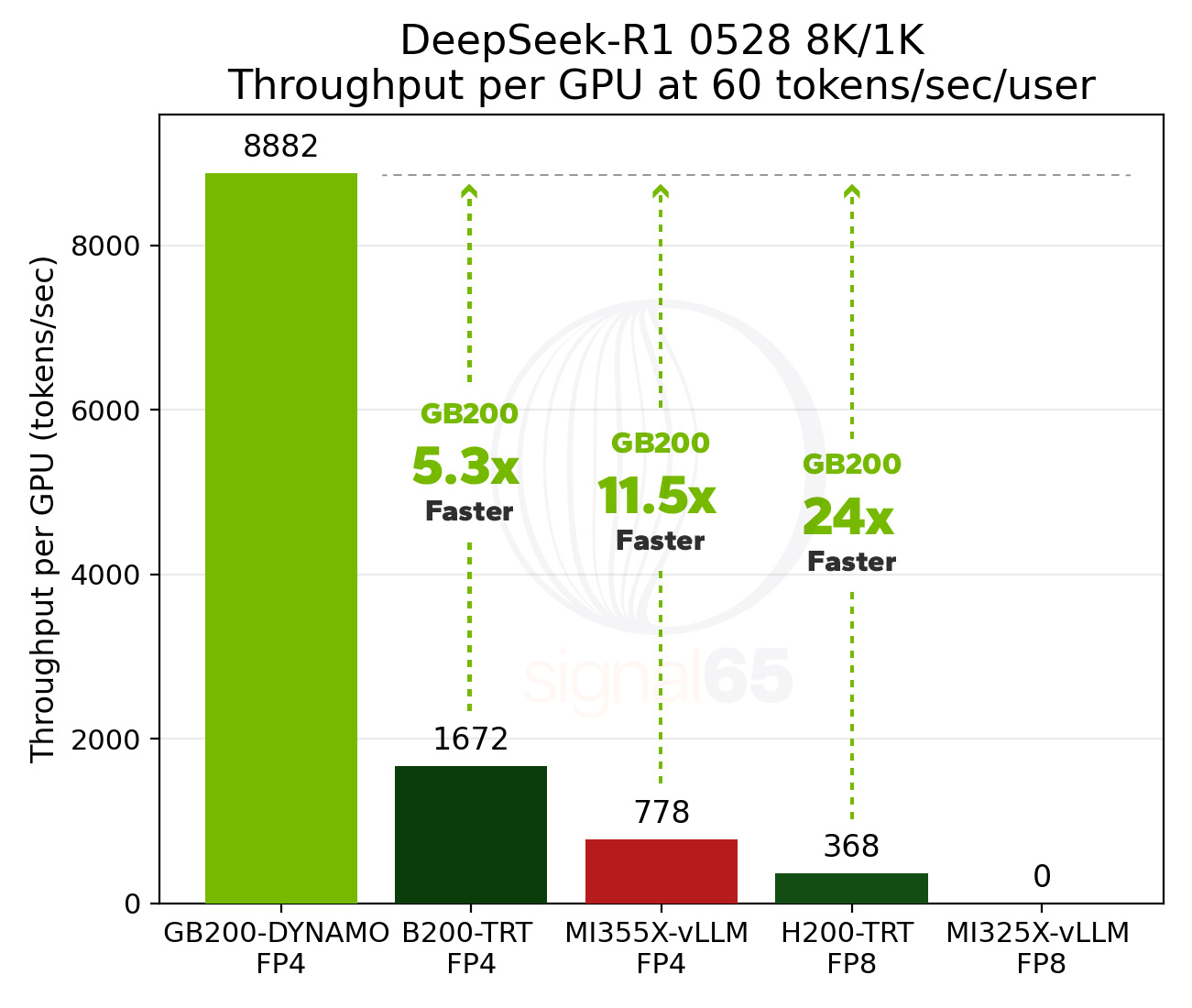
At a higher interactivity target of 60 tokens/sec/user, GB200 NVL72 delivers more than 24x generational improvement over H200 and nearly 11.5x the performance of AMD MI355X.
At 25 tokens/sec/user interactivity, GB200 NVL72 delivers approximately 2x the performance per GPU of B200 and 5.9x the performance per GPU of MI355X. At 60 tokens/sec/user, these advantages expand to 5.3x versus single-node B200 and 11.5x versus MI355X.
And though the H200 and MI325X platforms can’t 75 tokens/sec/user mark in the available data, the GB200 NVL72 is proving to be 6.5x faster than the B200 configuration and 28x faster than the MI355X platform, again on a per GPU basis.
Perhaps most significantly, GB200 NVL72 achieves interactivity levels that competitive platforms cannot reach at any throughput today. The system can deliver over 275 tokens/sec/user per GPU in a 28-GPU configuration, while MI355X peaks at 75 tokens/sec/user per GPU at comparable throughput levels.
Tokenomics Analysis
NVIDIA Generational Cost Comparison
In transitioning from the Hopper generation to the Blackwell generation with GB200 NVL72, NVIDIA not only increased compute, memory bandwidth, and NVLink interconnect bandwidth per GPU, it redesigned the system underlying architecture. By moving from 8-GPU air-cooled HGX servers to fully liquid-cooled rack-scale systems with 72 GPUs connected in a single domain, the cost and complexity of the systems definitely increased. Using published list pricing from CoreWeave, on a per-GPU basis, GB200 NVL72 is about 1.7x more expensive than H200. (Note that there are widely varying public pricing data points out in the market, from neoclouds to large CSPs.)
However, a goal with each new technology generation is to drive down the cost per token. For inference, specifically, this means increasing delivered token throughput by more than the underlying infrastructure cost increase. And this is exactly what we see with GB200 NVL72 compared to Hopper in the publicly available performance data.
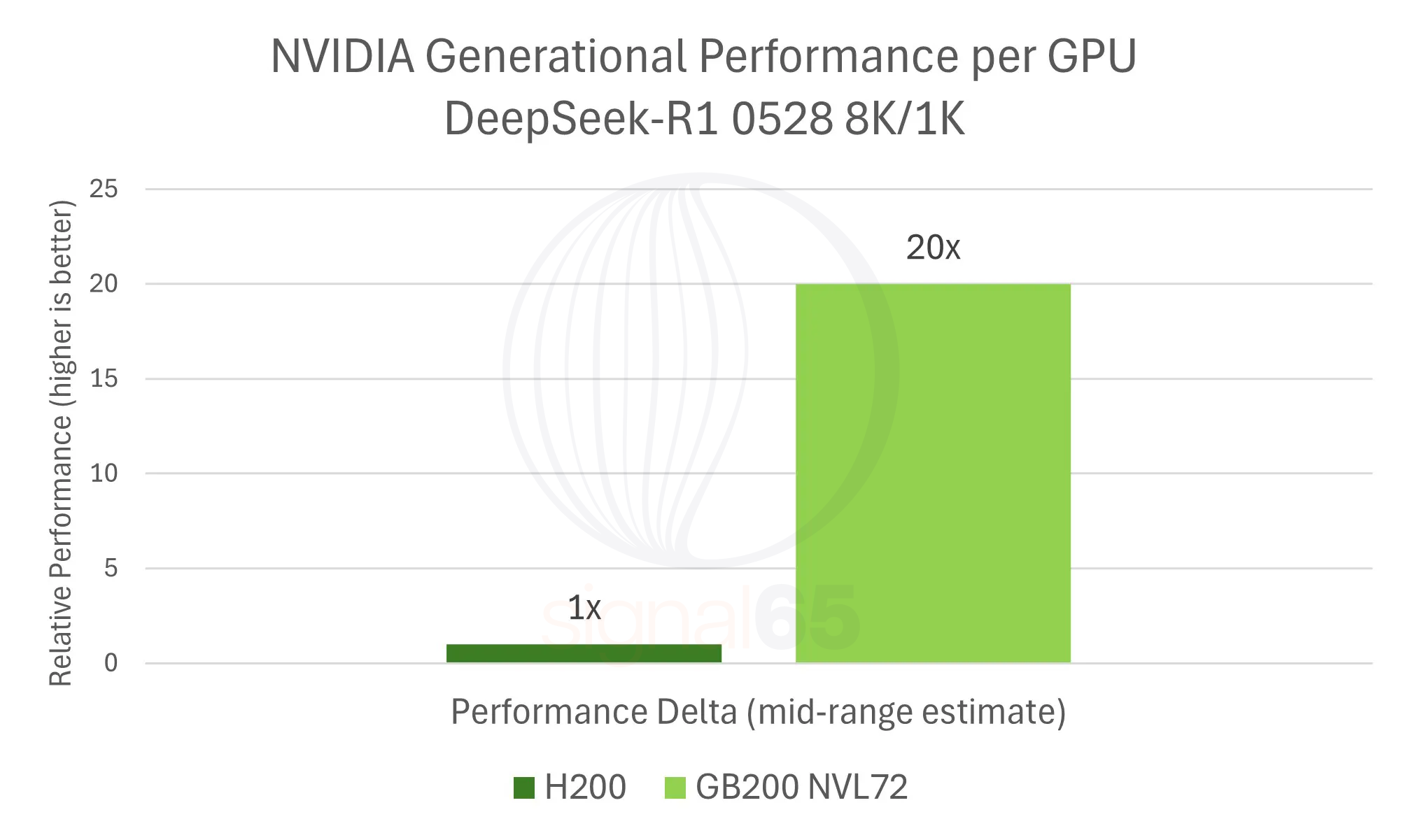
We anchor our “tokenomics” analysis on the DeepSeek-R1 performance deltas established earlier. At 25 tokens/sec/user, GB200 NVL72 delivers approximately 10x performance per GPU versus H200. At higher interactivity points, the delta grows larger (24x). For our moderate tokenomics summary, we use a general middle-ground delta of approximately a 20x generational performance increase, representing performance between our lower and higher interactivity bookends. (Obviously each use case will fall in a slightly different location along the Pareto curve, and thus mileage will vary on these TCO calculations.)
The following table summarizes the cost normalization and resulting performance-per-dollar calculations:
| Metric | GB200 NVL72 | H200 |
|---|---|---|
| CoreWeave List Price (per hour) | $42.00 (4-GPU) | $50.44 (8-GPU) |
| Normalized Cost per GPU-Hour | $10.50 | $6.31 |
| Price Ratio (GB200 vs H200) | 1.67x | 1.0x |
| Performance Delta (mid-range estimate) | ~20x | 1.0x |
| Performance per Dollar Advantage | ~12x | 1.0x |
| Relative Cost per Token | 1/12th | 1.0x |
The results here are initially counterintuitive: the more “expensive” platform is actually less expensive to operate and is able to generate tokens at lower cost due to the significant performance gains that are much larger than the pricing difference.
These calculations use published on-demand list prices. Reserved capacity and negotiated terms will change absolute dollar figures. This analysis is intended to demonstrate directional math and transparent methodology rather than precise cost projections for any specific deployment.

Competitive Cost Comparisons
For AMD platforms, the only location we have found that currently lists the pricing for MI355X publicly, along with GB200 NLV72 configurations, is Oracle Cloud.
| 25 Tokens/sec/user Interactivity | 75 Tokens/sec/user Interactivity | |||
|---|---|---|---|---|
| Metric | GB200 NVL72 | MI355X | GB200 NVL72 | MI355X |
| Oracle List Price | ||||
| Normalized Cost per GPU-Hour | $16.00 | $8.60 | $16.00 | $8.60 |
| Price Ratio (GB200 vs MI355X) | 1.86x | 1.0x | 1.86x | 1.0x |
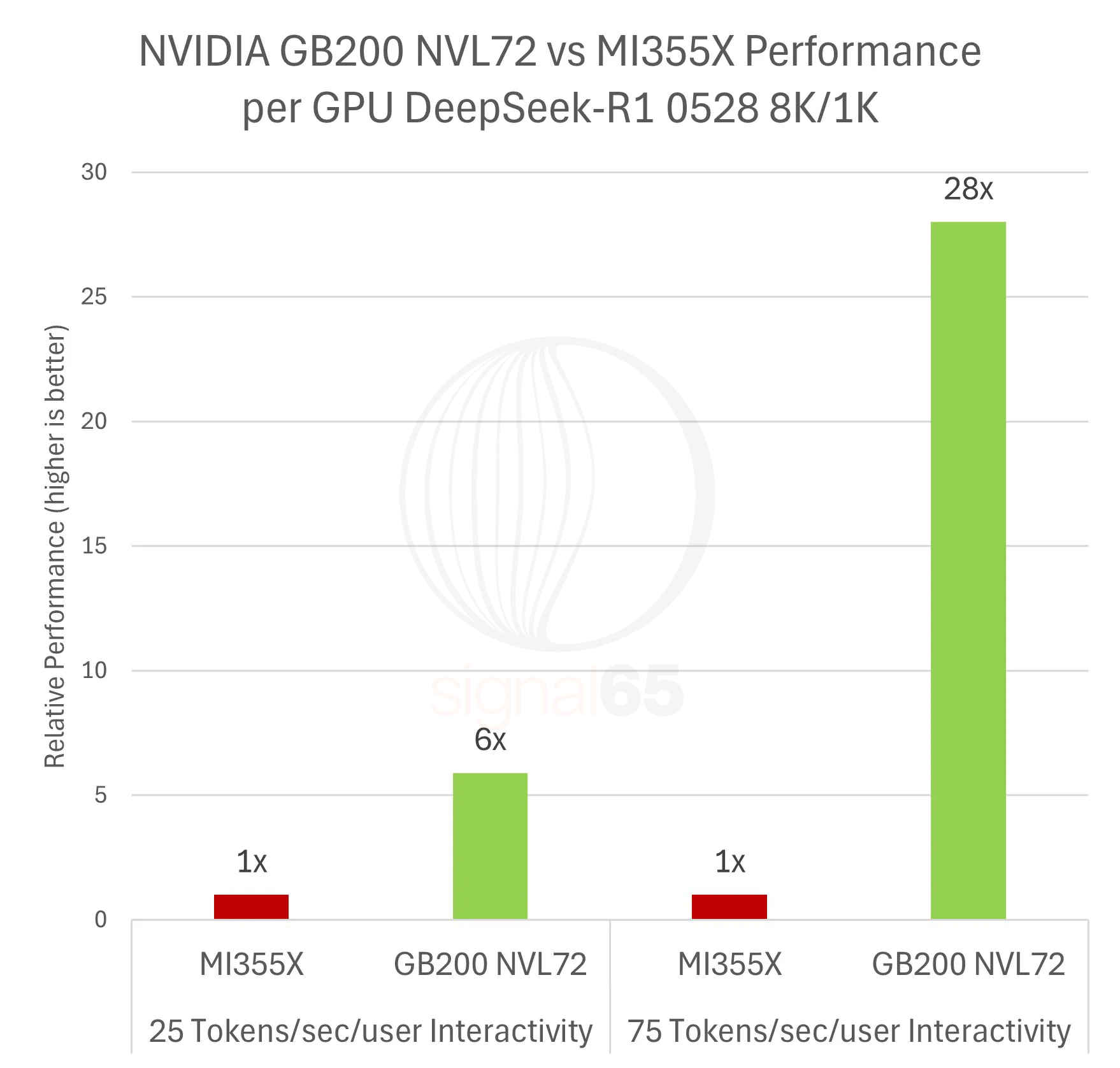
| Performance Delta | 5.85x | 1.0x | 28x | 1.0x |
| Performance per Dollar Advantage | 3.1x | 1.0x | 15x | 1.0x |
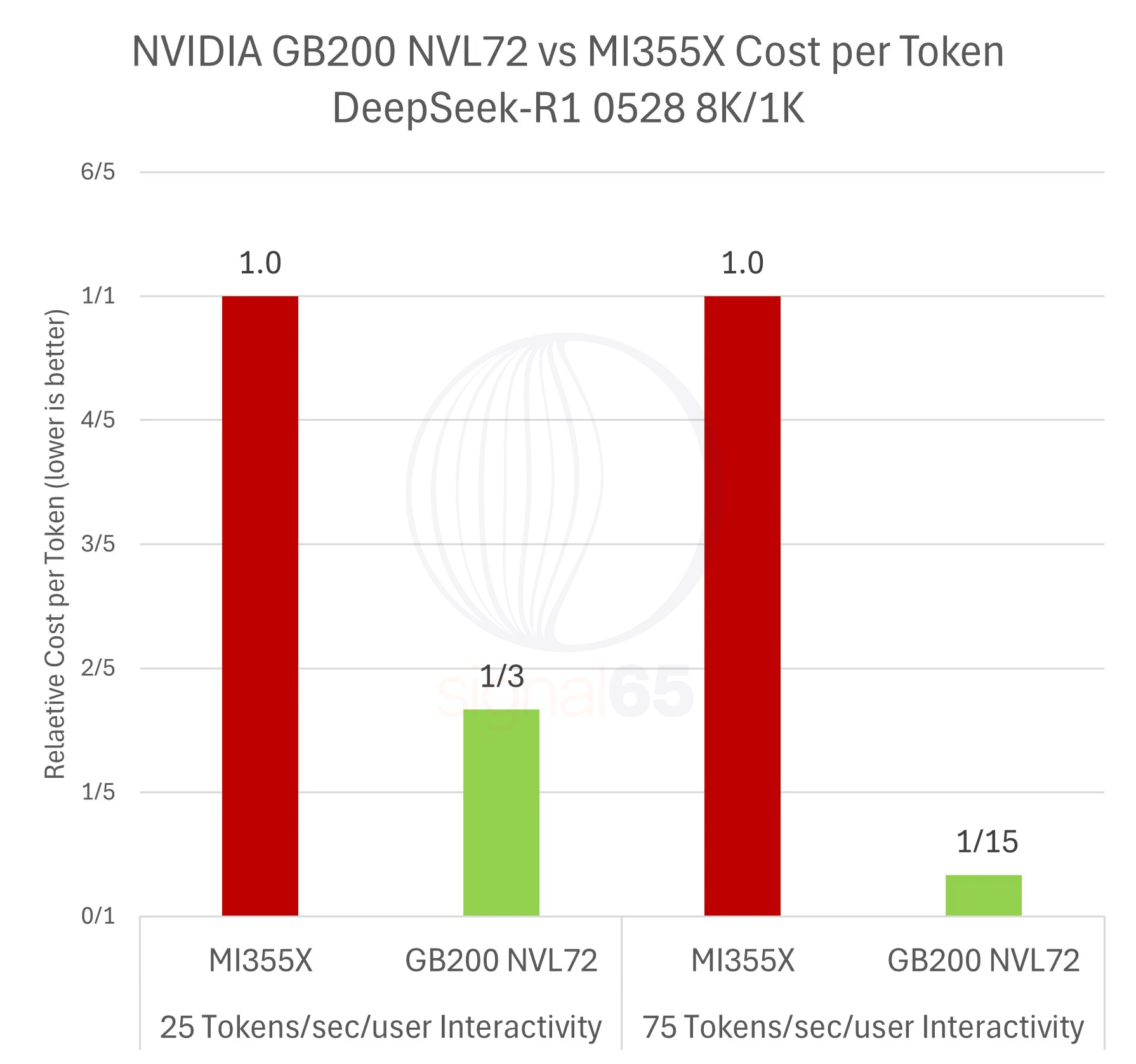
| Relative Cost per Token | 1/3rd | 1.0x | 1/15th | 1.0x |
On a per-GPU basis, the MI355X is roughly half the price of the GB200 NVL72 configuration, but since GB200 NVL72 provides a per-GPU performance advantage ranging from nearly 6x at the low end, to as high as 28x at a higher interactivity rate, the NVIDIA platform still offers up to 15x the performance per dollar compared to AMD’s current offering. Put another way, NVIDIA can offer a relative cost per token that is 1/15th that of the competition.
Obviously, AMD has room to improve in this space, and though we have seen an increasing rate of software updates and optimizations taking place on the Instinct series of GPUs, NVIDIA’s edge is significant when looking at leading edge model deployments. Our dense model, Llama 3.3 70B results analysis shows a narrower gap in pure performance that results in a better TCO narrative than MoE, but for hyperscalers and enterprises focused on sizable deployments, that may seem like looking backwards.
Conclusions
The future of frontier AI models is larger and more complex MoE. Sparse scaling represents one of the most practical paths to continuing capability and intelligence improvements. This shift elevates the importance of test-time compute and reasoning-style generation, raising the bar for infrastructure efficiency and scalability.
As models move deeper into MoE and reasoning architectures, outcomes depend on more than raw GPU performance or memory capacity. Platform-level design becomes the deciding factor, encompassing interconnect and communication efficiency, multi-node scaling characteristics, software stack maturity, ecosystem support and orchestration capability, and the ability to maintain high utilization under concurrency and mixed workloads.
Publicly available benchmark results indicate NVIDIA already holds clear advantages on strong dense models like Llama 3.3 70B. Those advantages increase dramatically as workloads shift to larger MoE models like DeepSeek-R1, where scaling and system design contribute more significantly to performance outcomes.
Based on current trends, flagship models from frontier vendors including OpenAI, Meta, Anthropic, and others will continue down the MoE and reasoning path. If this trajectory holds, NVIDIA maintains critical performance and economic advantages because the platform is optimized for precisely the stresses these model architectures introduce. Competitors like AMD are building out rack-scale solutions (Helios), and that may help close the gap sometime over the next 12 months. By then I do expect to see the NVIDIA Vera Rubin platform in production with the Ultra versions not far behind, coming in as NVIDIA’s fourth iteration of a rack scale design. Architectures like the Google TPU also offer rack-scale solutions, but their applicability to and performance on non-first-party models is unknown.
These results are a snapshot, not a final verdict on AMD competitiveness. AMD performance has moved meaningfully (as has NVIDIA), and MI325X and MI355X can be a fit where dense models and capacity-driven planning matter. As AMD continues to improve rack-scale architectures and software, gaps may narrow in parts of the curve, so buyers should keep validating with fresh data and real workload targets, something we at Signal65 will continue to monitor.
The performance differentials documented in this write up translate directly into measurable business outcomes. The more users served per deployed GPU at given interactivity thresholds lowers cost per useful token generated, increasing revenue potential per rack through delivery of higher-value experiences at scale, ultimately driving better TCO outcomes for AI service providers and enterprises deploying advanced reasoning services.
A concrete example illustrates the magnitude: when a platform can offer 28x better throughput per GPU at a given interactivity rate, it unlocks new product tiers and more complex functionality without requiring linear growth in hardware footprint. This is the tokenomics of AI inference, and it favors platforms designed from the ground up for the MoE and reasoning era.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}