NVIDIA DGX Spark First Look: A Personal AI Supercomputer on Your Desk
Ryan Shrout

Introduction: The Return of NVIDIA to Client-Side Computing
NVIDIA DGX Spark, internally codenamed Project DIGITS, marks the company’s bold return to building complete client-side computing systems. It’s essentially a desktop AI supercomputer powered by NVIDIA’s own silicon: a 20-core Arm-based Grace CPU tightly coupled with a Blackwell GPU on the same package. This combo harks back to NVIDIA’s ambitions of the past (like the Jetson dev kits and Tegra experiments) but now executed at a far grander scale for AI developers. By integrating an Arm CPU and cutting-edge GPU, DGX Spark represents a shift from NVIDIA’s traditional GPU-only offerings for the consumer into a full end-to-end system squarely aimed at AI development on the desktop. It brings the pedigree of NVIDIA’s data center DGX line (usually massive, multi-GPU servers) into a lunchbox-sized device meant for individual developers.
Historically, NVIDIA hasn’t offered a desktop with an NVIDIA CPU since the early Tegra-based kits, making DGX Spark a significant milestone. Jensen Huang described this concept as putting “an AI supercomputer on the desks of every data scientist, AI researcher and student”. In other words, DGX Spark is meant to democratize AI horsepower by providing a self-contained, developer-friendly machine that runs NVIDIA’s full AI software stack locally, without relying on cloud GPUs. This little gold box is essentially a slice of NVIDIA’s AI infrastructure, scaled down for personal use. It’s a response to the growing demand for local AI compute: as models grow in size and complexity, many developers hit limits with typical PC hardware (like insufficient GPU memory or lack of proper software environment) and are forced to rent cloud instances. DGX Spark’s mission is to eliminate that gap, to let you prototype, fine-tune, and run large models entirely on your desk. NVIDIA pitching this as a “new class” of device for AI builders makes sense: it’s neither a traditional PC nor a mere dev board, but a mini supercomputer designed from the ground up for AI workloads.
$4K for a Compact AI Dev Kit – Value Proposition and Performance
One of the most striking things about DGX Spark is its form factor and price. At $3,999 for the Founders Edition with 4 TB SSD, it’s expensive relative to consumer PCs, but remarkably accessible compared to NVIDIA’s other pro AI systems (which often cost tens of thousands). For that price, you get the entire NVIDIA AI ecosystem in a box: hardware, software, and support for the same frameworks and models used in the data center. In essence, Spark brings what used to require a server rack or cloud subscription into a device that sits quietly on your desk and plugs into a standard wall outlet. NVIDIA is clearly betting on the value of convenience and capability; that AI researchers and startups will pay a premium for a turnkey development platform with guaranteed compatibility and support.

From a pure performance standpoint, the DGX Spark raw GPU horsepower is in the ballpark of a mid-range discrete GPU, but it’s augmented by features that typical consumer cards lack. The Blackwell GPU in Spark delivers up to 1 petaflop (1000 TFLOPs) of AI compute at FP4 precision (with sparsity) – a metric that sounds astronomical, though it refers to low-precision operations used in AI. In more familiar terms, its FP16/FP32 throughput is closer to an upper-mid-tier GeForce card (think an RTX 5060- or 5070-class chip). Indeed, some early argued that Spark’s compute itself isn’t magical. However, the key advantage of Spark is its 128 GB of unified memory, which dwarfs the VRAM of any GeForce card. This means you can load enormous models or multiple models concurrently without running out of memory – a massive boon for AI development. NVIDIA itself highlights that this 128 GB LPDDR5x pool (shared seamlessly between CPU and GPU) lets DGX Spark work with AI models up to ~200 billion parameters locally. In practice, that means tasks like running a 120B language model or a suite of vision models together, jobs previously reserved for multi-GPU servers, are now feasible on a single desktop unit.

It’s also worth noting that Spark’s Arm CPU (Grace) is no slouch either. The 20-core chip (with 10 high-performance Cortex-X925 cores and 10 efficiency Cortex-A725 cores) holds its own against modern x86 CPUs. In Geekbench 6.5 tests, the DGX Spark’s CPU scored around 3120 points single-thread and 18,895 multi-thread, slightly edging out an AMD “Strix Halo” Ryzen AI 395 chip (which scored ~2883 single and 17,442 multi) in our comparisons. So, the Grace CPU is roughly on par with high-end laptop/workstation CPUs, ensuring that data preprocessing and CPU-bound parts of AI workloads won’t bottleneck the GPU. The takeaway: DGX Spark’s value isn’t raw TFLOPs alone, but the balanced design: ample compute, massive memory, and a complete software stack, all tuned for AI developers’ productivity.
Specifications at a Glance
To understand what DGX Spark offers, let’s break down its core. This “personal AI supercomputer” packs impressive tech into its tiny 1.2 kg chassis:
NVIDIA Grace 20-core Arm SoC (10x Cortex-X925 + 10x Cortex-A725) – 64-bit Armv9 architecture
NVIDIA Blackwell architecture GPU (GB10 Superchip) – 5th-gen Tensor Cores, 4th-gen RT Cores
~1 PFLOP (1,000 TOPS) at FP4 precision (with sparsity)
128 GB LPDDR5X unified system memory (CPU+GPU shared), 256-bit bus, 273 GB/s bandwidth
4 TB NVMe M.2 SSD (PCIe Gen4) with optional self-encryption
(1 TB SSD in base models from OEM partners)
10 GbE Ethernet (RJ-45) integrated
ConnectX-7 SmartNIC (200 Gb/s InfiniBand/RDMA over Ethernet) for clustering
4x USB-C ports (USB 3.2/4 spec) 1x HDMI 2.1a display output (supports monitors/TVs) Wi-Fi 7 and Bluetooth 5.3 wireless
NVIDIA DGX OS (Linux, Ubuntu-based) preloaded – includes full NVIDIA AI software stack (CUDA, cuDNN, TensorRT, RAPIDS, etc.)
150 mm x 150 mm x 50.5 mm (LxWxH) – about the size of a small router
External 240 W power adapter (AC) ~170 W typical draw under load; active cooling (small fans) with ~35 dB noise under max load.
Looking at these specs, a few things stand out. The Grace+Blackwell “Superchip” architecture means the CPU and GPU share memory coherently via NVLink-C2C, giving Spark its unified memory advantage. This design is similar to what NVIDIA deploys in its HGX/Grace-Hopper servers, just scaled down. The ConnectX-7 NIC is an interesting inclusion, it isn’t just a gimmick; it allows two DGX Sparks to be linked at 200 Gb/s for essentially doubling the memory and compute. NVIDIA supports clustering two units to handle models up to ~405 billion parameters (using distributed inference) In other words, if one Spark isn’t enough, you can add a second and connect them via RDMA to tackle truly enormous models, a feature clearly borrowed from the DGX cluster playbook.

On the I/O side, DGX Spark is well-equipped for a small box: four USB-C ports can handle peripherals or even external GPUs (in theory), and an HDMI 2.1 output means you can plug it into a monitor and use it like a normal computer. The inclusion of Wi-Fi 7 is forward-looking, though for serious use the wired 10 GbE or 200 Gb networking will be preferred. The device’s physical build is also notable, it’s a dense little unit with a textured metal finish and DGX branding. The design mimics the “cheese-grater” gold front of the DGX Station, but miniaturized. Spark can operate either horizontally or vertically, and at ~1.2 kg it’s portable enough to move between office, home, or lab. Power consumption is stated up to 240 W; in practice we saw ~170 W under heavy AI loads, which is modest compared to multi-GPU rigs but definitely more than a typical mini-PC. Overall, the spec sheet paints the Spark as a no-compromise AI dev kit; you’re essentially getting a slice of NVIDIA’s latest datacenter technology (Blackwell GPU + NVLink + Grace CPU) in a desktop package.
NVIDIA’s Positioning: DGX Spark in the NVIDIA AI Ecosystem
How is NVIDIA framing the DGX Spark? In their own messaging and the official reviewer’s guide, it’s clear they see Spark as “a new class of computing device” designed explicitly to build and run AI workloads locally. Rather than marketing it as just a mini PC, NVIDIA calls it a “personal AI supercomputer” meant for developers, researchers, and even students. The core pitch is that DGX Spark brings consistency across development stages: you prototype on Spark and later deploy to larger DGX servers or cloud instances seamlessly, since it’s the same CUDA-based software stack underneath. In other words, Spark is the entry-point to the NVIDIA AI ecosystem on your desk, ensuring that what you develop locally will run at scale on NVIDIA’s bigger systems without code changes or environment hassles.
NVIDIA emphasizes a few key points in positioning Spark:
- Bridging Edge and Cloud: There’s a recognition that many AI developers start on laptops or desktops with limited GPUs, then move to cloud or cluster for bigger tasks, a context switch that can be painful. Spark is meant to eliminate that gap by providing enough local horsepower (1 PFLOP, 128GB) so you can do serious prototyping entirely on-premise. They cite the issues of “lack of local GPU memory or compute” and the expense of cloud resources as pain points Spark addresses. Having a Spark means you don’t need to constantly borrow time on a shared cluster for medium-sized models.
- AI Stack and Tools Ready Out-of-the-Box: DGX Spark comes with DGX OS, a custom Ubuntu-based Linux with all the NVIDIA drivers and AI frameworks pre-installed. CUDA, cuDNN, TensorRT, PyTorch, TensorFlow, JupyterLab, NVIDIA AI Workbench, it’s all there from first boot. NVIDIA wants devs to “hit the ground running” using the same tools they’d use on a full DGX Station or in DGX Cloud. This is a significant differentiator from rolling your own PC + GPU setup, where environment configuration can eat days of setup time. Spark even has support for newer open-source tools like vLLM (for optimized LLM inference), TRT-LLM (TensorRT for Large Language Models), and containerized workflows. In essence, NVIDIA is positioning Spark as turnkey AI development infrastructure for individuals.
- Agentic and Generative AI Focus: NVIDIA’s messaging also highlights that Spark is ideal for the latest trends in AI, such as agentic AI (AI agents that plan and converse) and reasoning models. The reviewer’s guide talks about running multiple models concurrently for multi-agent systems and mentions that Spark’s 128GB memory allows for concurrent LLMs and vision models to enable complex AI workflows. This aligns with how NVIDIA likely expects Spark to be used: not just training a single model from scratch, but orchestrating several pre-trained models to build AI applications. For example, you might have a chatbot agent using a 70B LLM, a vision agent using a specialized model, and a code agent, all running together on one Spark. NVIDIA even provides sample “AI playbook” demos that showcase these scenarios, underscoring that Spark is meant to fuel innovative AI use-cases rather than raw number-crunching alone.
In summary, NVIDIA is positioning DGX Spark not as a niche toy, but as a foundational tool for AI development, something a research lab, a small startup, or even an advanced enthusiast might standardize on. It’s the AI equivalent of a high-end dev workstation, with the selling point that it speaks NVIDIA’s “language” fluently (no surprise, since they control the whole stack here). The company’s messaging is that Spark “democratizes” AI hardware by condensing a supercomputer’s capabilities into a small, (relatively) affordable box. Whether $4K is truly democratic is debatable, but for those who do get a Spark, NVIDIA is ensuring they become part of an ecosystem, one that will likely drive cloud usage and sales of larger systems down the road.
Hands-On Experience: Setup, Playbooks, and First Tests
Setting up the DGX Spark in our lab was refreshingly straightforward for such a cutting-edge device. NVIDIA clearly put effort into a smooth out-of-the-box experience. We tried Desktop Mode first: connecting a monitor via HDMI and a keyboard/mouse to the USB-C ports. Within seconds, an installation wizard appeared on-screen, guiding us through user account creation, network setup, and a brief tutorial. The entire initialization took maybe 5–10 minutes, including downloading a few updates. Impressively, if you prefer headless operation, Spark supports a “Network Appliance Mode” where it broadcasts a temporary Wi-Fi hotspot for setup. We tested this as well using a laptop: we connected to Spark’s hotspot and a browser-based setup page popped up (no cables needed) to configure Wi-Fi and finalize the install. This is very similar to how you’d set up a smart home device or router, and it worked flawlessly in our case. After setup, the device joined our office network and we could access it via SSH and the web-based DGX Dashboard.
Ease of use is clearly a priority. Once booted, DGX Spark runs a custom Ubuntu-based OS (DGX OS) with a lightweight GUI. Firefox opened automatically to NVIDIA’s build portal with a welcome message and prompt to explore sample playbooks (we had a pre-release password to access them). NVIDIA provides a curated set of “AI playbooks” (essentially step-by-step guides with example code) covering common workflows. For instance, right from the dashboard we could launch JupyterLab or VS Code and try notebooks for things like:
- Stable Diffusion image generation via ComfyUI (a web interface for diffusion models)
- LLM inference using TensorRT-LLM and Ollama (to serve a language model)
- Fine-tuning a model with PyTorch Lightning
- “Unsloth” optimization – an example playbook on speeding up model training
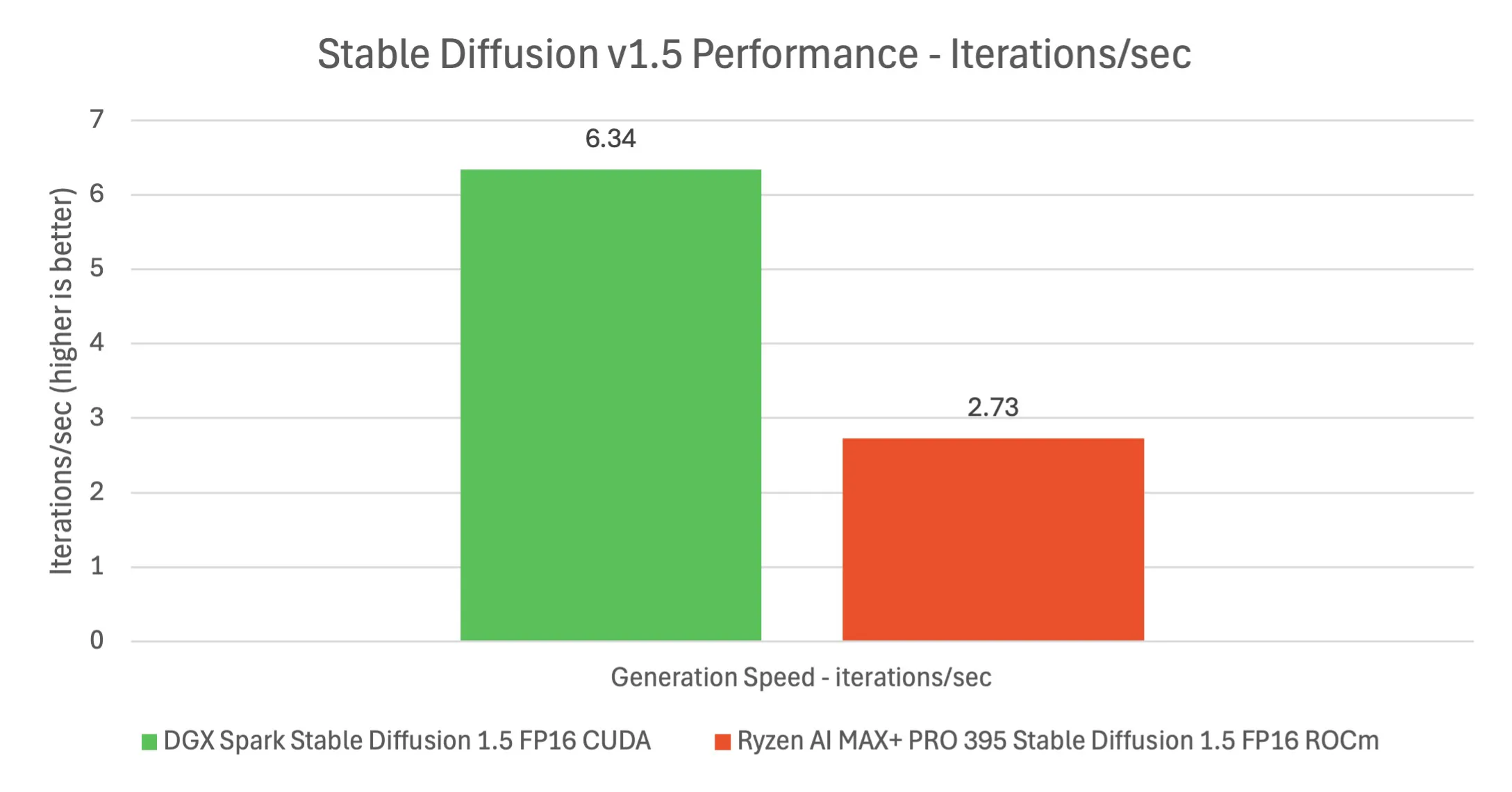
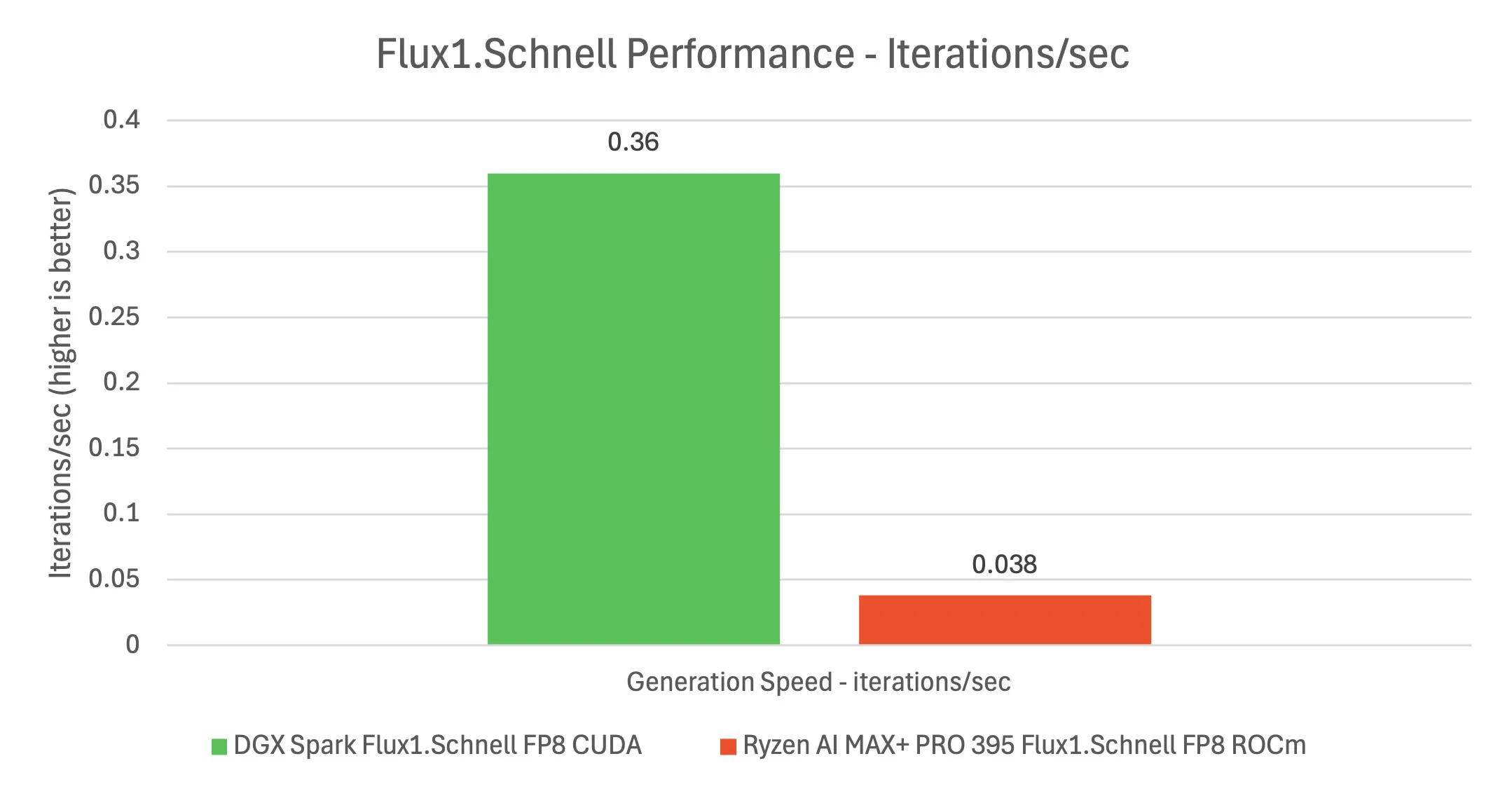
These playbooks were extremely useful for initial testing. Within a container on the Spark, ComfyUI spun up and we were generating images in minutes. The process was seamless, all the needed Docker containers and models were pulled automatically. In our tests, the DGX Spark churned out Stable Diffusion 1.5 images at about 19 images per minute (512×512 with default settings), which is roughly 6.3 iterations per second. For comparison, a recent AMD Strix Halo APU system (Ryzen AI Max 395 with integrated RDNA graphics) managed only ~8 images/min (2.7 it/s) on the same workload. So Spark was about 2.3x faster at stable diffusion inference than that high-end AMD chip, and in fact slightly faster than an NVIDIA RTX 4070 GPU we benchmarked earlier (which does ~5 it/s on SD1.5). The experience was practically plug-and-play, a testament to the well-built software environment. All drivers and libraries (CUDA, cuDNN, TensorRT) were correctly set up out of the box, and NVIDIA’s containerization of the workflow meant we had no dependency issues. It’s clear NVIDIA expects many Spark users to use containers and provided examples to avoid the “it works on my machine” syndrome.
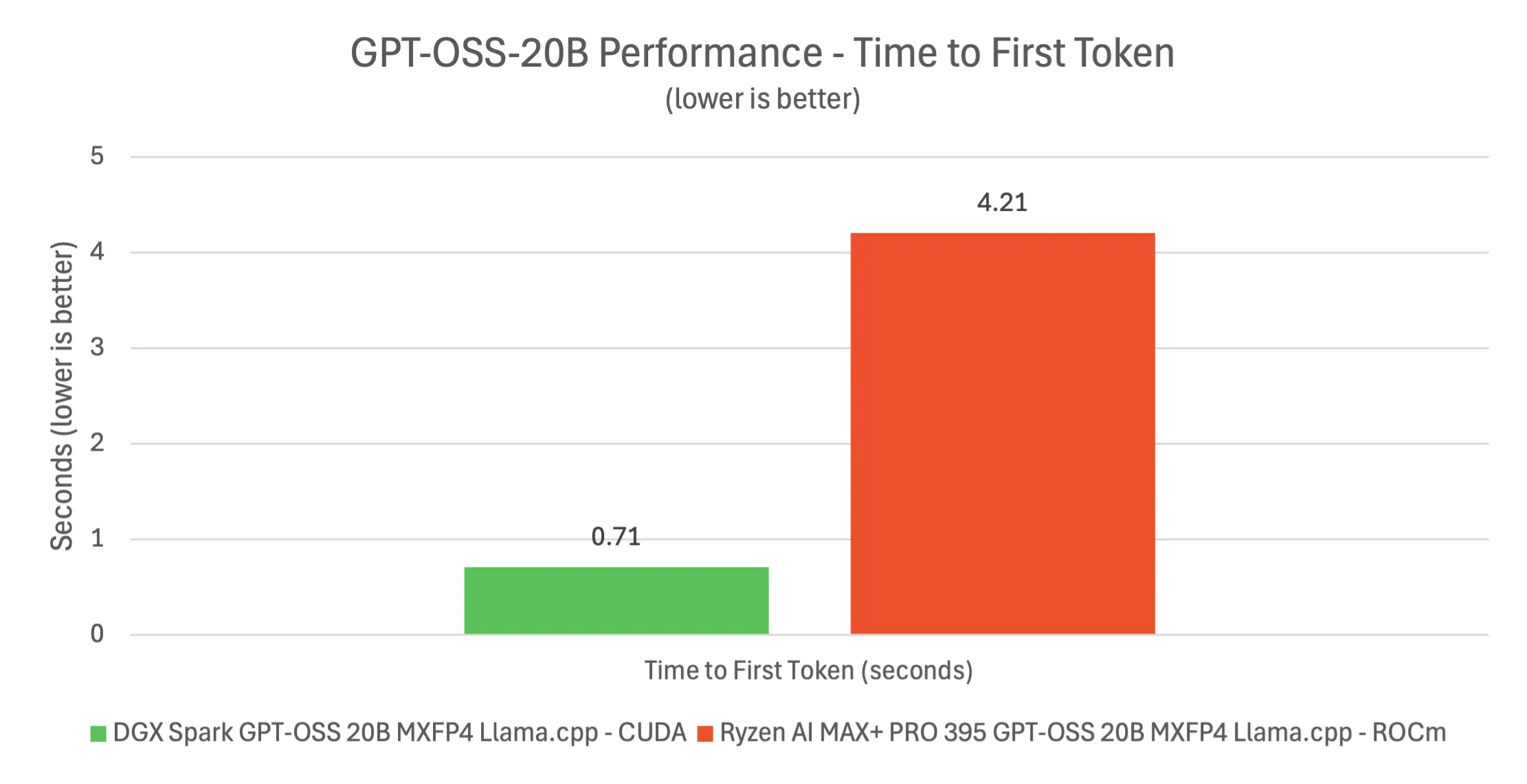
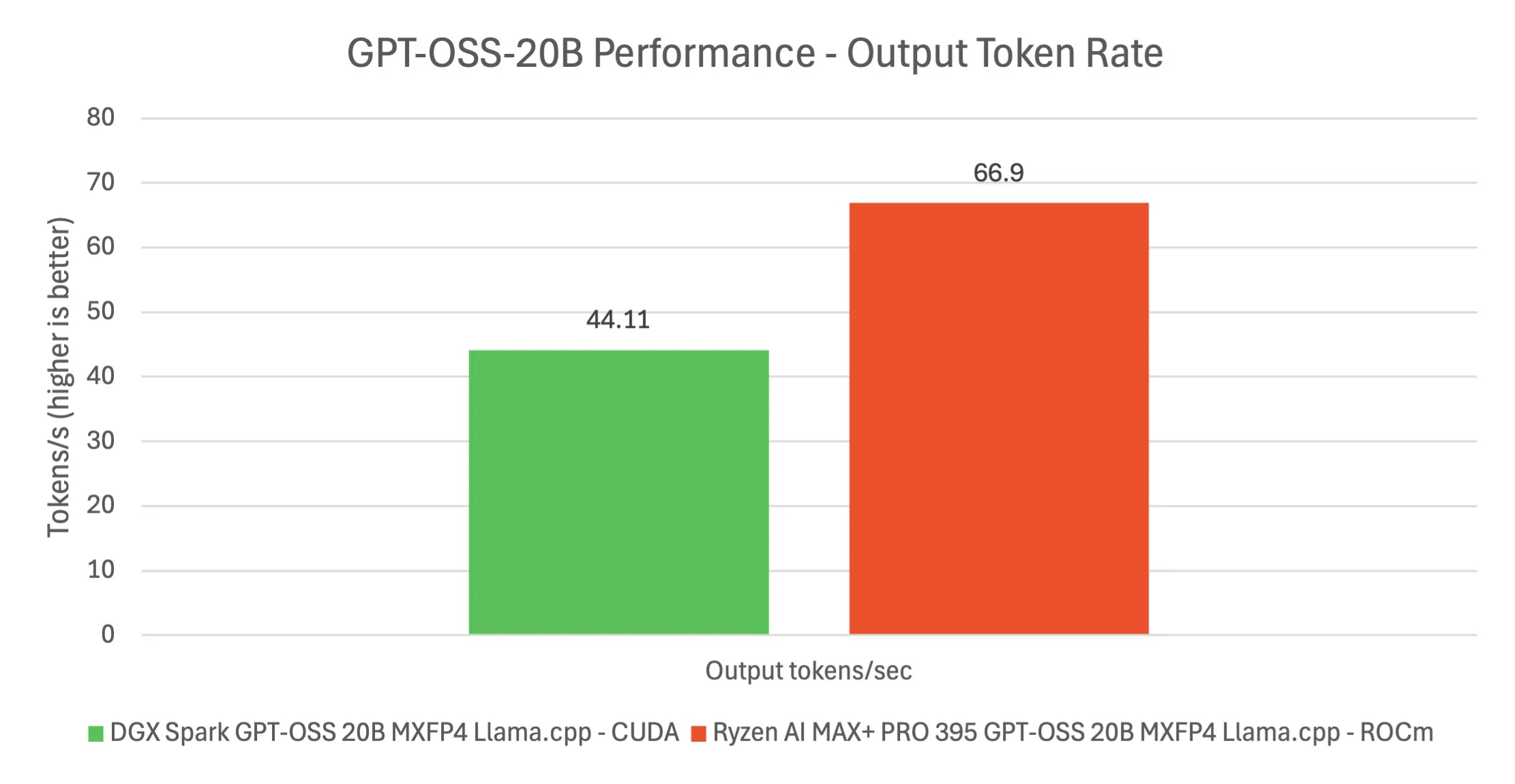
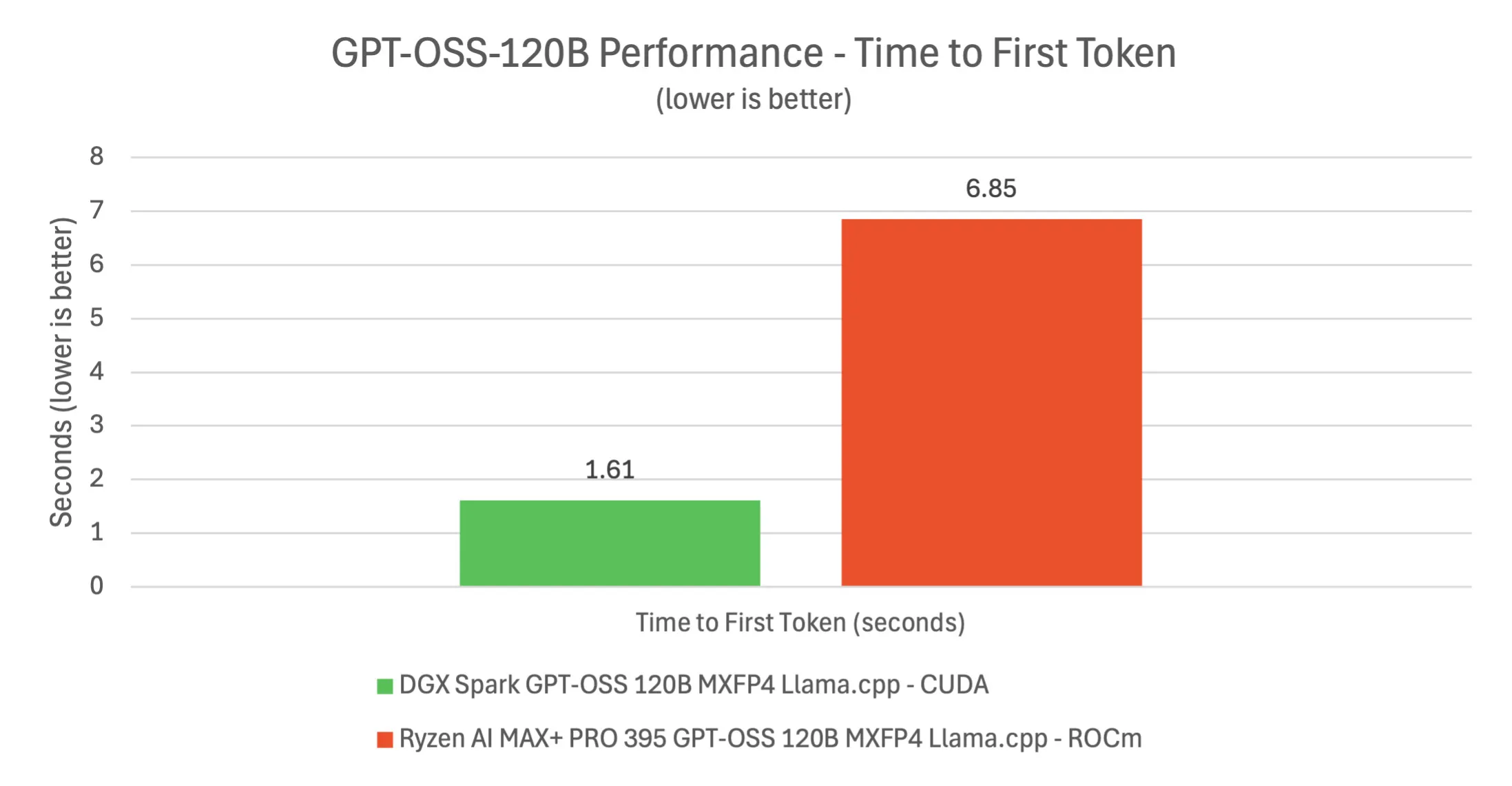
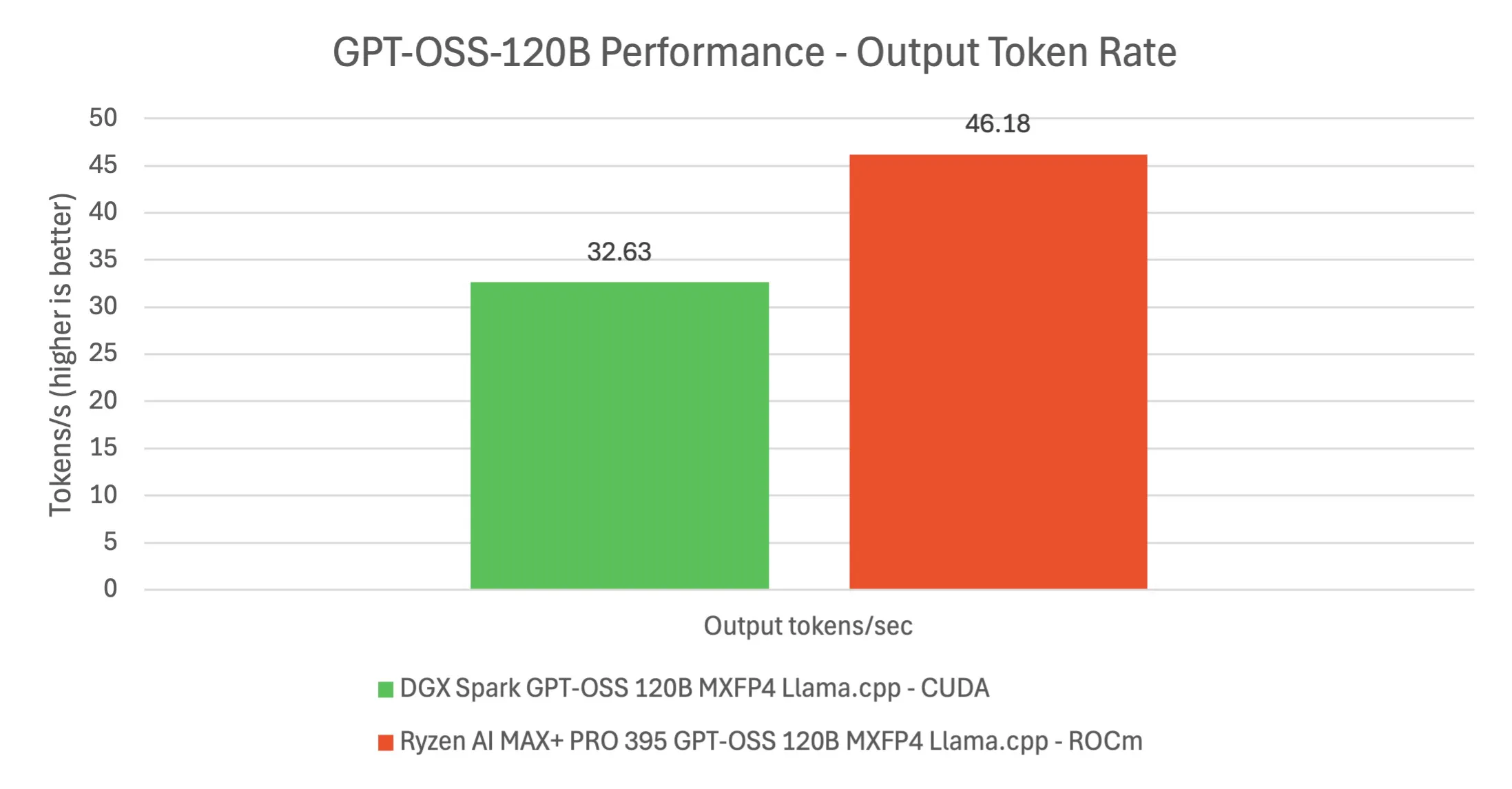
Next, we dove into what is arguably the Spark’s biggest use case: running large language models locally. One of the showcase demos was the GPT-OSS 120B parameter model. We deployed this on the DGX Spark, and it was genuinely impressive to see a 120B model running entirely on a single desktop machine, something essentially impossible until now. The 120B model (a GPT-J/OPT class open-source model) was loaded in 4-bit quantized form and served via NVIDIA’s optimized frameworks (a combination of TensorRT-LLM and llama.cpp backends). Thanks to the 128GB unified memory, the model fit with room to spare. The time-to-first-token for the 120B model was about 1.6 seconds in our tests using a CUDA-accelerated pipeline, whereas an AMD Strix Halo system took over 6–7 seconds for the same (using ROCm on its iGPU). Once generation started, Spark produced text at roughly 32–33 tokens per second for the 120B model. Interestingly, the AMD system sometimes hit slightly higher steady token/sec (~46/sec), but that is with a significant delta and disadvantage in latency and TTFT.
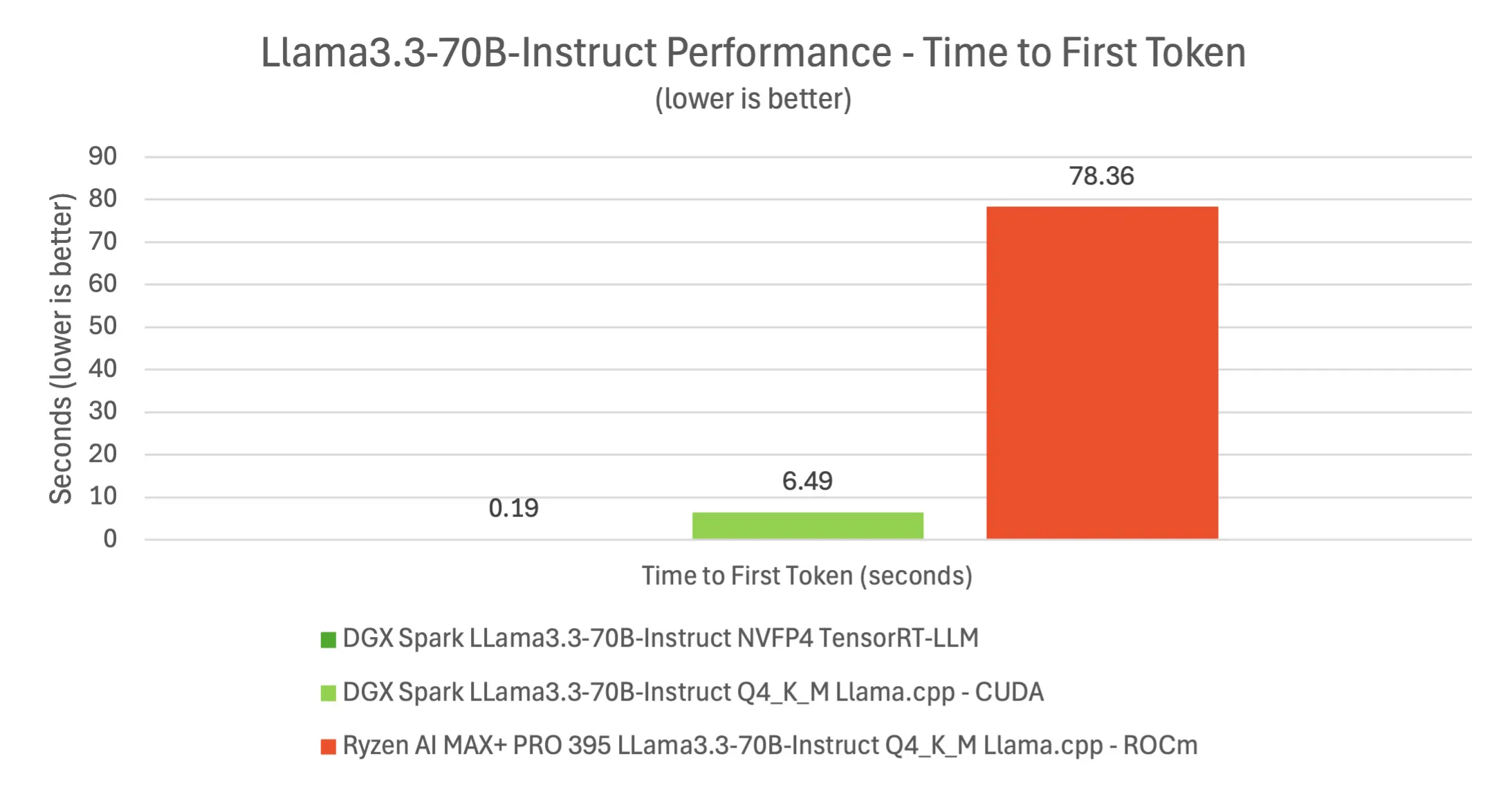
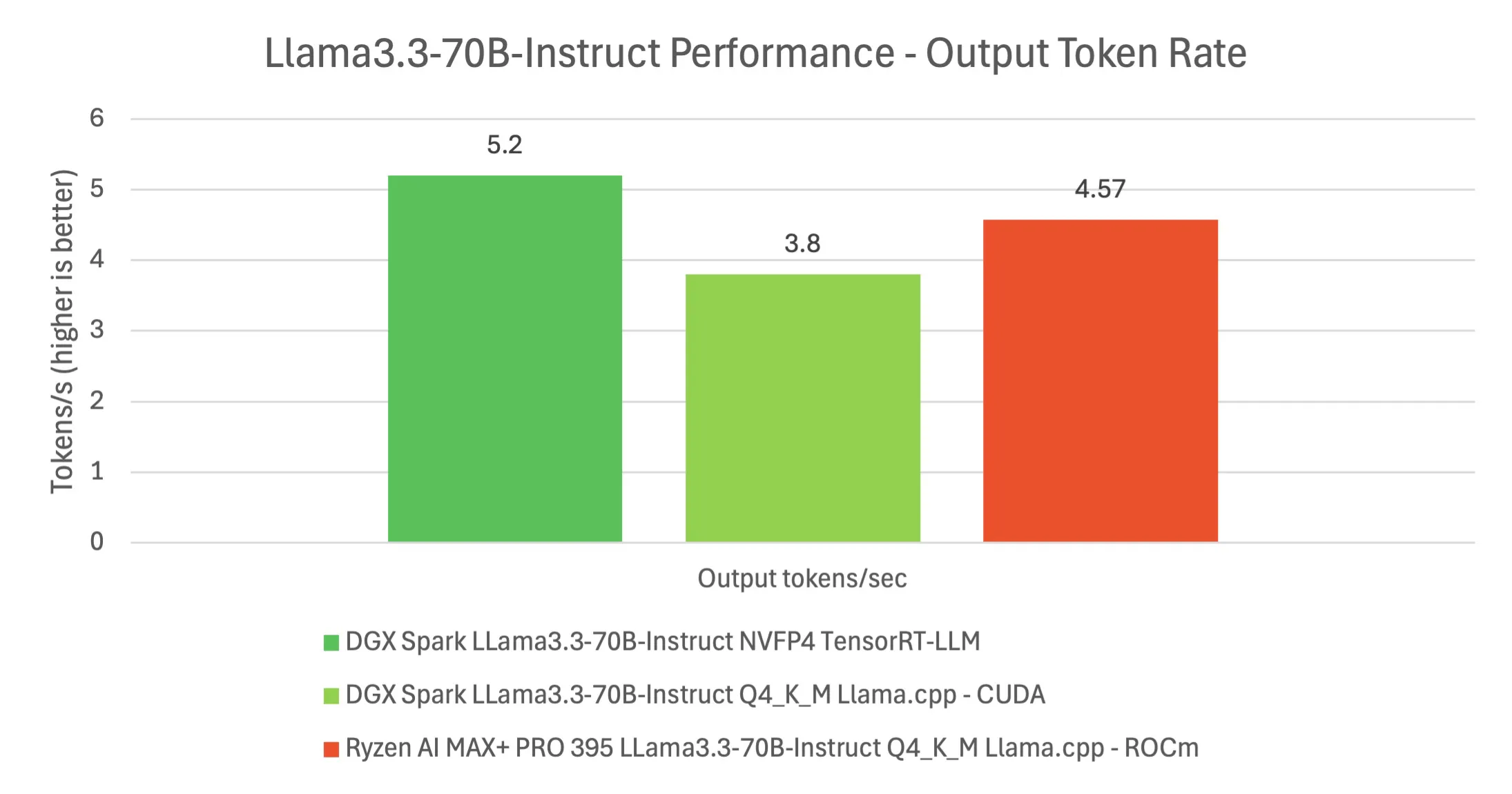
We also performed some more traditional benchmarks for good measure. Using the Llama 70B model (an instruct-tuned variant), we evaluated Spark’s performance in different modes. With NVIDIA’s FP4 TensorRT-LLM engine, the 70B model ran at ~5.2 tokens/sec generation, and astonishingly the first token arrived in under 0.2 seconds. In contrast, running the same 70B model in 4-bit integer mode via llama.cpp on Spark gave ~3.8 tokens/sec and about a 6.5 s first-token latency (reflecting the overhead of the CPU offloading during quantized decoding). Meanwhile, the AMD Strix Halo platform struggled with the 70B model: using 4-bit quantization on ROCm, it achieved ~4.6 tokens/sec but took a painful 78 seconds to emit the first token. This underscores how DGX Spark’s specialized hardware and software (FP4 support, TensorRT) make a tangible difference on larger models. In practical terms, working with a 70B or 120B model on Spark felt interactive (if not blazing fast), whereas on the AMD system it was borderline impractical due to the long initialization and slower throughput for the bigger models.
- Software Stability: The DGX OS environment was stable and very developer-friendly. Docker was pre-installed with the NVIDIA container runtime, and many sample containers were provided. We never had to compile CUDA or fiddle with driver versions, a welcome change from typical DIY GPU rigs.
- Memory Management Quirks: Because of the unified memory, some tools (especially older versions of PyTorch or drivers) don’t fully understand the shared memory pool. In certain cases, after heavy allocation and deallocation, we noticed memory not being freed back to the system immediately. NVIDIA’s documentation actually mentions this and provides a simple workaround: flushing the buffer/caches can manually free up the unified memory if an app doesn’t release it. We encountered this once when a failed run of a large model left ~20GB allocated. Running the suggested command cleared it up. It’s a minor hiccup that is likely to be optimized in future software updates, but worth noting if you push the memory limits.
- Thermals and Throttling: The Spark’s chassis does get warm to the touch under load, but we did not observe thermal throttling in our tests. The Grace CPU in particular can boost aggressively, in single-threaded tasks it clocked up and delivered performance above what we expected from an Arm core. Under multi-core loads, the clocks moderate to keep within the power envelope. The GPU similarly maintained its performance; Blackwell is built for efficiency, and it shows. The device’s fan noise is just noticeable at full tilt (a soft whir, comparable to a gaming laptop) but in idle or light use it’s near silent.
Overall, the initial hands-on experience with DGX Spark has been extremely positive. NVIDIA has managed to wrap bleeding-edge hardware into a package that, from a user perspective, feels as easy as setting up a new Mac Mini or workstation. The provided playbooks and examples lowered the barrier to getting meaningful results on day one, we were generating images and chatting with local LLMs in the first hour of testing. This speaks to the polish of the platform. There’s a sense that Spark is not just a mini-PC; it’s a complete development kit. From hardware to drivers to sample code, it’s all been integrated and tested together. That said, this is still a first look, we’ve only scratched the surface of what we plan to test (we haven’t even attempted many training or fine-tuning runs yet, which will be interesting given the FP8/FP16 capabilities vs. memory bandwidth). But so far, using DGX Spark has been like having a slice of an AI lab on our desk, with surprisingly few headaches.
Conclusion: First Impressions and What’s Next for Signal65
Our preliminary time with the NVIDIA DGX Spark reveals a compelling, if premium-priced, tool for AI developers. In many ways, Spark feels like a culmination of NVIDIA’s strategy to cover the full AI stack from the data center to the desk. By leveraging their latest silicon (Grace CPU and Blackwell GPU) and coupling it with a polished software ecosystem, NVIDIA has created something unique: a personal AI development machine that doesn’t compromise on capability. It truly blurs the line between a workstation and a server. One moment we’re using it like a normal desktop (browsing Jupyter notebooks, writing code in VS Code), and the next moment it’s crunching through Transformer models that would normally live in a data center, all on the same little box.
Is the DGX Spark worth the $3,000–$4,000 price tag? For the average hobbyist tinkering with AI, it’s a lot of money; you could buy a couple of high-end GPUs for that, or pay for quite a lot of cloud GPU hours. But for AI professionals, research labs, or startups, the value proposition is clearer. You get a known-good platform with NVIDIA’s full support (and likely enterprise support options via NVIDIA AI Enterprise, etc.), reducing dev friction. The ability to iterate on large models locally, keep data in-house (for privacy), and have a portable unit to carry between collaborations is significant. During our tests, we kept remarking how a task that used to require scheduling time on a server could now be done at our desk immediately. There’s an agility in that which is hard to quantify in dollars.
That said, DGX Spark is not a magic bullet. Its GPU, while powerful, is still a single GPU, training truly massive models from scratch or doing multi-GPU parallel jobs is beyond its scope. It’s not meant to replace a multi-node GPU cluster for production training; it’s a dev and prototyping machine. NVIDIA knows this; Spark is positioned as the “prototyping and inference” solution, with an easy path to scale up on cloud or bigger DGX when needed. In some sense, one could view Spark as a feeder for NVIDIA’s cloud business: get every dev using NVIDIA hardware locally, which in turn nudges them to use NVIDIA cloud offerings for larger scale runs, ensuring end-to-end NVIDIA reliance. Strategic motives aside, for the end-user it means consistency and fewer surprises when moving workloads around.

From a broader industry perspective, DGX Spark also hints at NVIDIA’s consumer ambitions. This device is clearly targeting professionals, not gamers or casual users. Yet, one can’t ignore the proximity to consumer space, a small desktop with an NVIDIA chip could, in theory, be sold to enthusiasts or creators too. It raises the question: will we see a more consumer-friendly variant someday (perhaps with less memory or a different branding)? And how will competitors respond? AMD’s already in the game with Strix Halo. Even Apple has been touting its unified memory and Neural Engine, albeit on a smaller scale of AI models. NVIDIA entering client-side computing again with Spark could spur a new segment of “AI PCs.” It could influence the workstation ecosystem, with Dell, Lenovo, or HP bundling NVIDIA Grace/Blackwell boards into workstations next year. In fact, NVIDIA has signaled that OEM partners will incorporate Grace-Blackwell tech into their products. So Spark might be the first swallow of spring, so to speak.
In conclusion, our Signal65 first look finds that DGX Spark delivers on its promise: it’s a petaflop-class AI dev kit that is actually usable and useful on day one. It’s fast enough, it’s well-engineered, and it embodies NVIDIA’s vision of AI development being ubiquitous. Of course, it’s also a version 1.0. The coming months will tell how software updates improve it and how the community embraces it (or finds quirks). We will continue to test DGX Spark rigorously, this report is just the beginning. Expect a more comprehensive analysis soon, where we’ll dig into training workloads, multi-GPU clustering, and more nuanced discussions about where client-side AI computing is headed. We’ll also explore the implications for the client CPU/GPU market: Does Spark indicate NVIDIA inching towards broader consumer hardware (an “AI PC” for creators?), or will it remain a niche pro device? How might this influence workstation designs from other vendors? And importantly, what does it mean for developers, will having such power locally change how AI models are developed and deployed?
For now, our verdict is that NVIDIA DGX Spark is an impressive first-of-its-kind: a tiny gold box that packs a punch and signals the next step in AI’s march from the cloud to the edge. It’s not cheap, and it’s not for everyone, but for those who need it, it’s a game-changer. Stay tuned for more, where we’ll push DGX Spark to its limits and report back on how it shapes the future of AI computing on the desk.