This blog provides a preview of our testing and analysis of the Intel Gaudi 3 AI accelerator implementation on IBM Cloud, with a full report coming soon.
Over the last couple of years, generative AI has demonstrated its immense potential as a revolutionary technology. AI powered applications have shown to enhance automation, streamline workflows, and rapidly increase innovation. Further, the technology has proven to be broadly applicable, with opportunity for the creation of new, intelligent applications across virtually every industry. While the value of generative AI is apparent, the powerful hardware required to run such applications is often a barrier. As AI is increasingly moving from an experimental trend to the backbone of real world applications, IT organizations are challenged with balancing the necessary performance with economic considerations of AI hardware, and doing so at scale.
To evaluate the benefits of Gaudi 3 on IBM Cloud, Signal65 has conducted a series of AI inferencing performance tests across Intel Gaudi 3, NVIDIA H100, and NVIDIA H200 based IBM Cloud instances. Each environment was tested with three distinct models with several configurations of input sizes, output sizes, and batch sizes to create an early evaluation. All testing was completed using vLLM as an inferencing server, due to its high performance and broad model and hardware compatibility. The models tested include:
This model selection represents a wide range of sizes and computational requirements, as well as enterprise applicability. Initial testing has shown Gaudi 3 can offer highly competitive performance to both NVIDIA H100 and NVIDIA H200 devices. The figures below, while only with limited specific input, output, and batch size configurations, highlight the competitive performance achievable with Gaudi 3 on IBM Cloud. We do expect to see a broader, more comprehensive view of Gaudi 3 performance and the competitive comparisons in our upcoming full report.
Note: We realize that this testing only represents a small intersection of possible configurations of input/output sizes, batch sizes, and parallelism across the tested models. These results are intended to be a preview of a more in-depth analysis of the Guadi 3 implementation on IBM Cloud, available in an upcoming Signal65 Lab Insight Report.
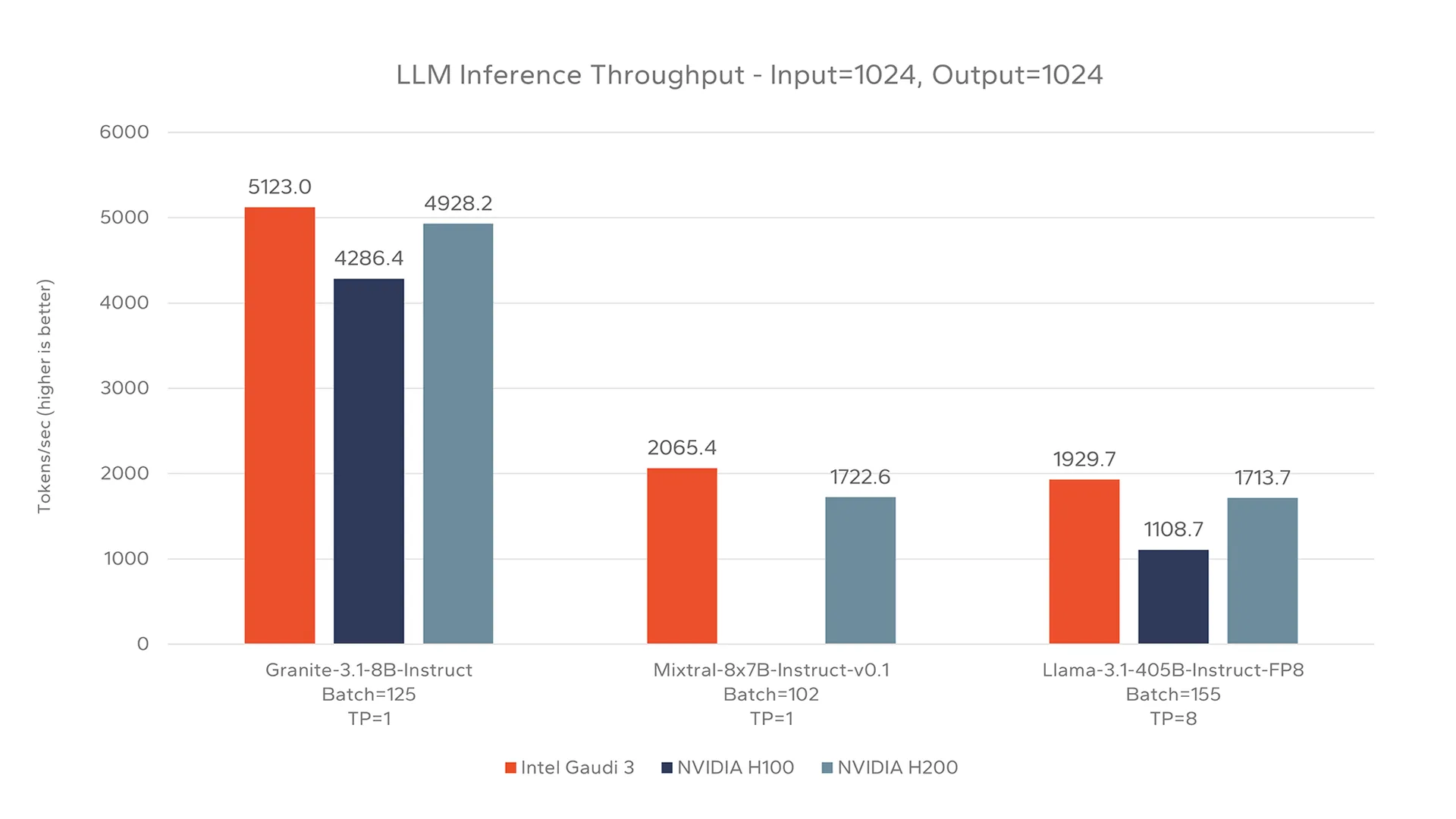
This chart showcases the ability of Gaudi 3 to achieve higher throughput than H200 and H100 for both the Granite and Llama models tested in specific shapes (input, output, batches, parallelism). Testing of Mixtral-8x7B in this specific configuration showed Gaudi 3 to outperform the H200, while the H100 was unable to run the model on a single card. These individual tests demonstrate a baseline of performance, utilizing medium sized input and output, however, the requirements of real world AI use cases often vary. To analyze the performance of Gaudi 3 on IBM Cloud, further testing was done for each model at various input, output, and batch sizes.
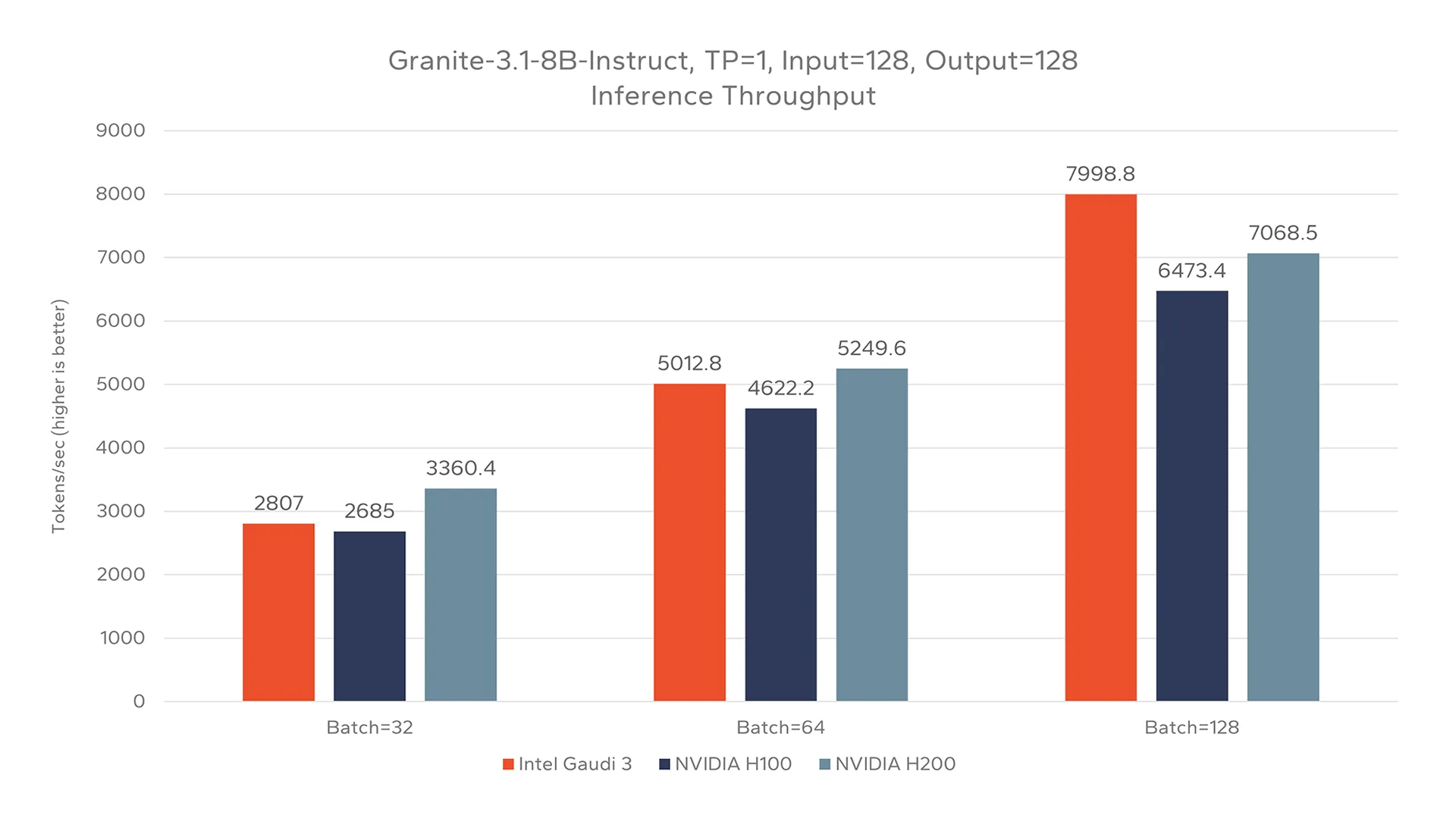
Figure 2 showcases the performance of each device running Granite-3.1-8B-Instruct with relatively small input and output sizes using a range of batch sizes. This type of small input, small output configuration may be utilized for scenarios such as text classification or lightweight chat applications, that do not utilize techniques that require larger context windows such as RAG.
When tested with a small input and small output on Granite-3.1-8B-Instruct, Gaudi 3 consistently outperformed NVIDIA H100, with slightly lower throughput than NVIDIA H200. Notably, the relative performance of Gaudi 3 was seen to improve as batch sizes grew.
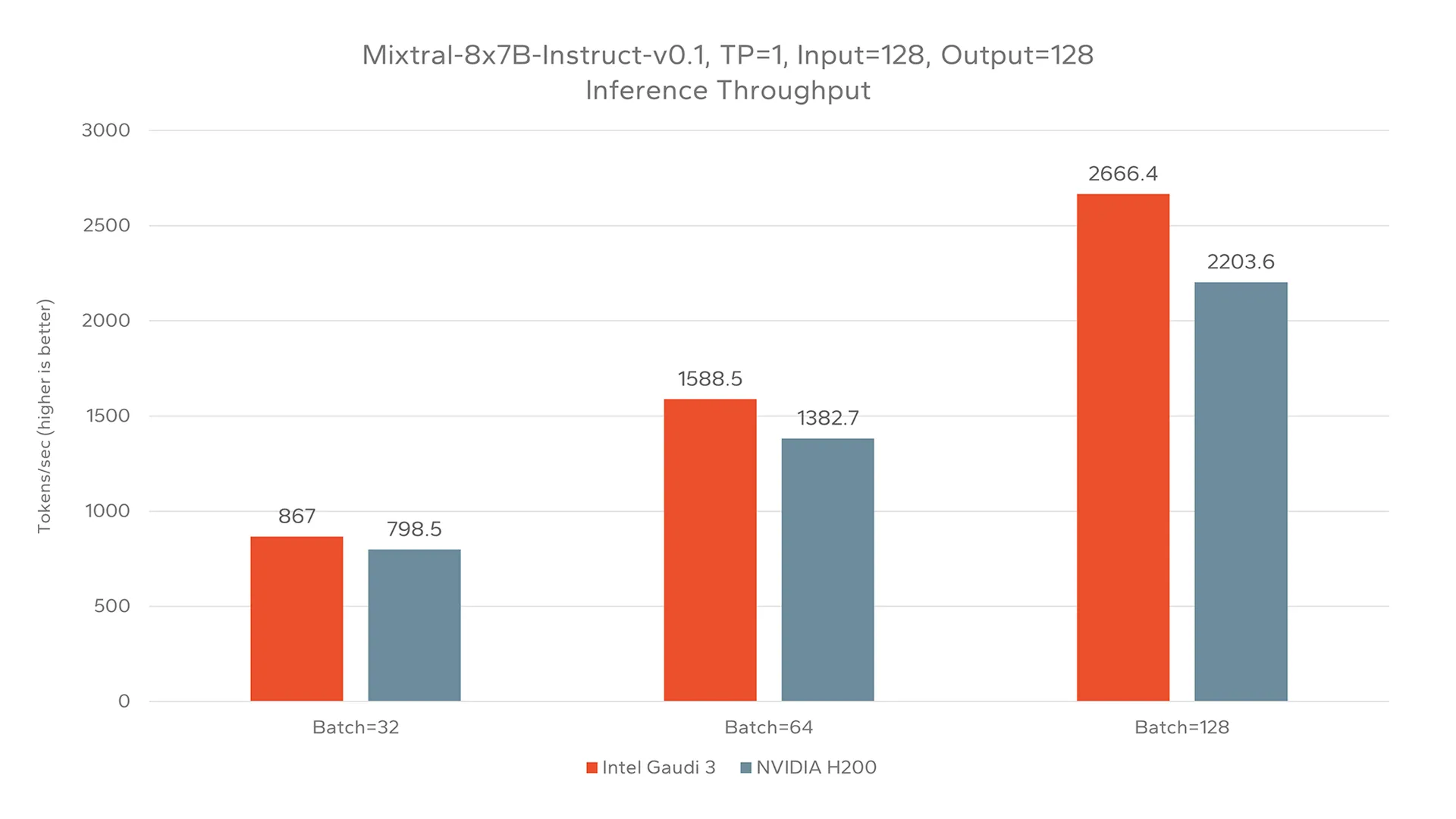
When evaluating inferencing of Mixtral-8x7B at the same small input, small output size, Gaudi 3 achieved a higher performance than NVIDIA H200 at three distinct batch sizes, as depicted in Figure 3. Notably, NVIDIA H100 was omitted from this testing as Mixtral-8x7B was unable to run on a single H100 card.
Similar to the testing of Granite-3.1-8B-Instruct depicted in Figure 1, the relative performance of Gaudi 3 was seen to increase with larger batch sizes. For this configuration, Gaudi 3 achieved throughputs between 8.5% and 21% higher than the NVIDIA H200.
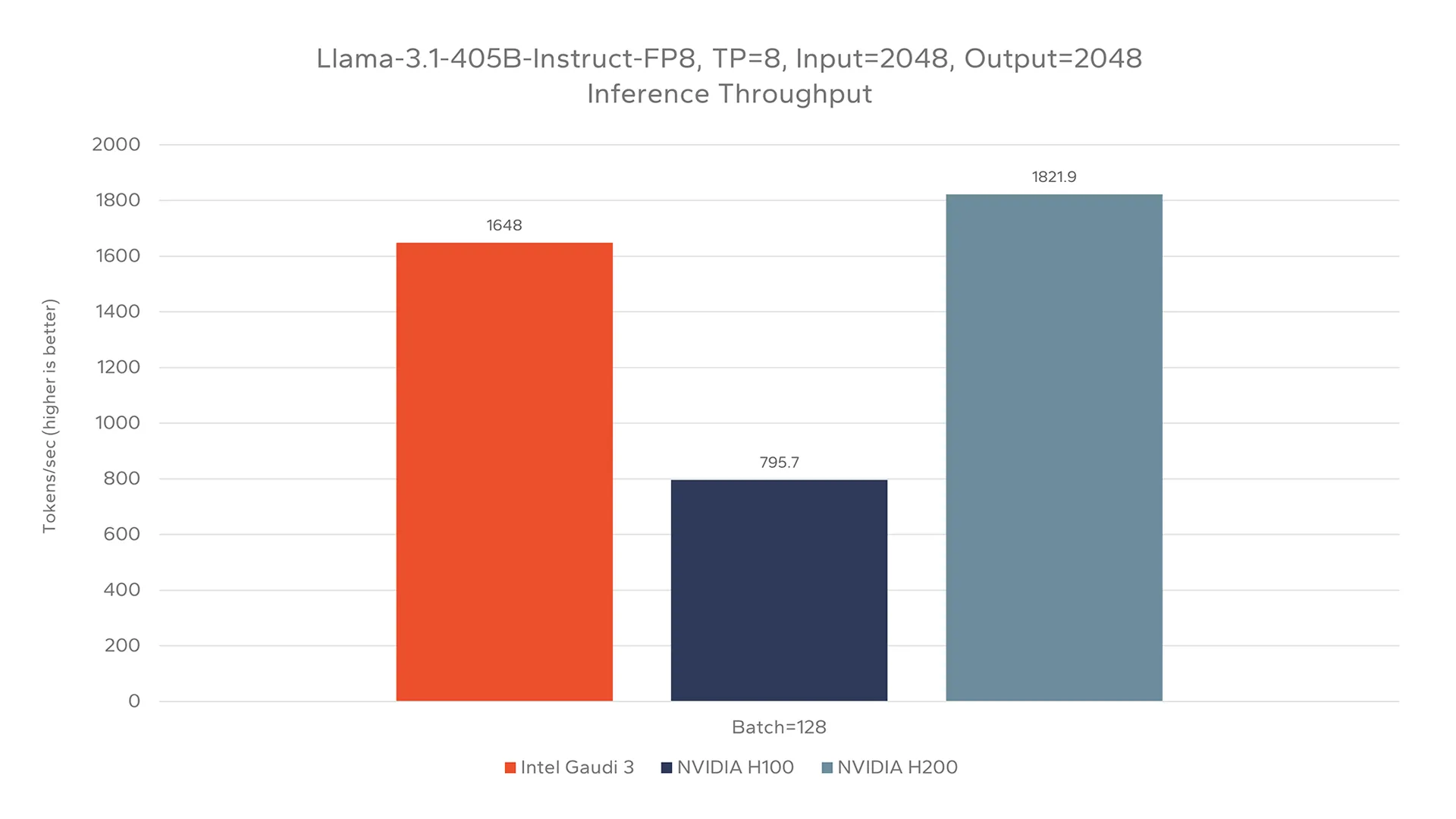
Testing of Llama-3.1-405B evaluated the capability of each device to run a very large, state of the art language model. For this evaluation, an FP8 quantized version of Llama-3.1-405B was evaluated. Figure 4 shows a throughput comparison of each device when tested with a large input and large output, all at a batch size of 128. Handling such large shapes is of an increasing importance as AI applications grow more complicated. Utilization of techniques such as RAG or complex agents can dramatically increase input context, while complex tasks such as code development may additionally require large output sizes.
This evaluation demonstrates an incredibly resource intensive configuration, utilizing a large, high quality model, and large input and output sizes. While the NVIDIA H200 instance demonstrates the highest overall throughput in this scenario, Gaudi 3 once again maintains competitive performance, within 10%. Compared to the NVIDIA H100, Gaudi 3 was found to achieve 107% higher throughput.
Gaudi 3 maintains highly competitive performance against NVIDIA H200 and H100 across a wide range of configurations, showcasing its broad applicability to various AI use cases.
This testing demonstrates that Gaudi 3 maintains highly competitive performance against NVIDIA H200 and H100 across a wide range of configurations, showcasing its broad applicability to various AI use cases. While Gaudi 3 did not achieve the highest individual performance for every test configuration, the value of Gaudi 3 on IBM Cloud becomes apparent when considering the economics of each solution.
Even with competitive performance numbers across all three devices, Gaudi 3 instances are available on IBM Cloud at a significantly lower rate, $60 per hour, compared to both NVIDIA instances at $85 per hour.
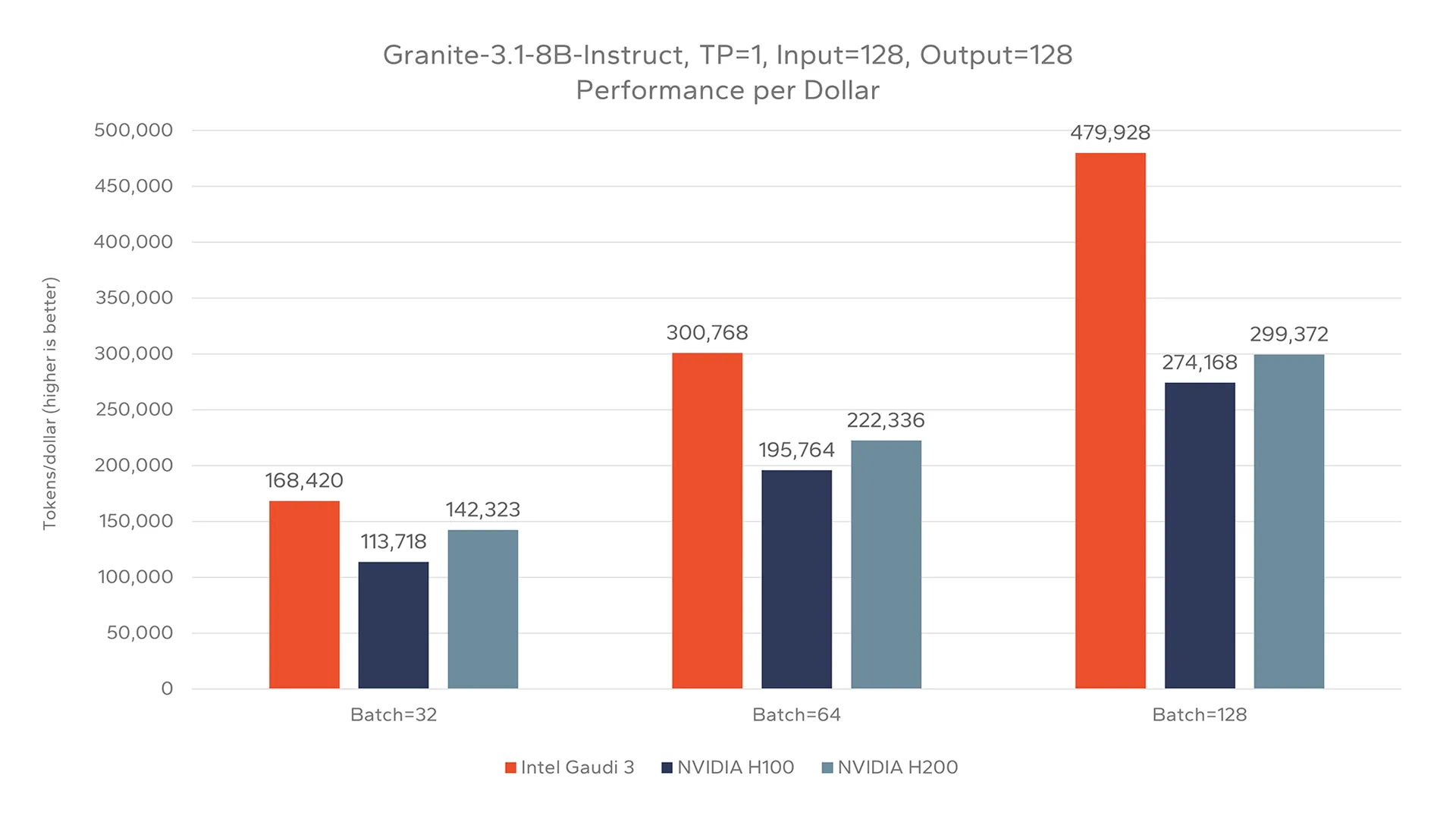
Revisiting the testing of Granite-3.1-8B-Instruct shown in Figure 2, the economic advantage becomes clear when adjusting the results to evaluate the tokens per dollar achievable by each solution. While the pure tokens per second performance results for this test placed Gaudi 3 between the two NVIDIA devices, Figure 5 shows Gaudi 3 is capable of offering a far higher rate of tokens per dollar. When scaled to a batch size of 128, Gaudi 3 was found to be 60% more cost efficient than NVIDIA H200 and 75% more cost efficient than NVIDIA H100.
Evaluating an AI model with 128 input and output tokens and large batch sizes closely mirrors real-world workloads that demand low latency and high throughput. This setup is common in environments like token-limited APIs, edge devices, or scenarios where quick responses to short inputs are essential.
It’s particularly well-suited for short-form tasks such as sentiment analysis, named entity recognition, text embedding generation, and tabular predictions. These workloads often involve compact inputs, like tweets, support tickets, or structured rows, and require minimal output, making them ideal for batching at scale, in areas like customer service, fraud detection, or recommendation engines. Overall, this testing scenario highlights how AI models can be optimized for speed and volume in practical, production-grade applications and shows an area where Gaudi 3 could excel.
The availability of Intel Gaudi 3 AI accelerator instances in IBM Cloud presents an appealing opportunity for IT organizations struggling to balance both the cost and performance requirements of their emerging AI workloads. In addition, by deploying Gaudi 3 on IBM cloud, these resources are made easily accessible and scalable, enabling organizations to accelerate their AI implementations.
Intel Gaudi 3 AI accelerators can achieve up to a 1.6x performance per dollar advantage over the NVIDIA H200 on tested AI models and configurations.
This preliminary performance testing conducted by Signal65 found Intel Gaudi 3 to offer highly competitive performance when compared to alternative NVIDIA-based offerings on IBM Cloud. Gaudi 3 on IBM Cloud provides a flexible platform capable of achieving high performance across various models and technical configurations. In addition, the pricing of Gaudi 3 instances on IBM Cloud builds an appealing economic advantage over both NVIDIA instance types. Signal65 initial measurement demonstrates that Intel Gaudi 3 AI accelerators can achieve up to a 1.6x performance per dollar advantage over the NVIDIA H200 on tested AI models and shapes. For large models, Signal65 found Gaudi 3 to significantly outperform NVIDIA H100 and offer competitive performance to NVIDIA H200, while at a 30% lower cost on IBM Cloud.
When combining its highly competitive performance with its appealing economics, Intel Gaudi 3 on IBM Cloud offers an attractive option for deploying AI workloads at scale.
Be sure to follow up with Signal65 for our full, more detailed performance analysis where we will expand our models and testing methods to see a broader, more comprehensive view of Gaudi 3 performance and the competitive comparisons.
Note: We realize that this testing only represents a small intersection of possible configurations of input/output sizes, batch sizes, and parallelism across the tested models. These results are intended to be a preview of a more in-depth analysis of the Guadi 3 implementation on IBM Cloud, available in an upcoming Signal65 Lab Insight Report.
 Mitch Lewis
Mitch Lewis